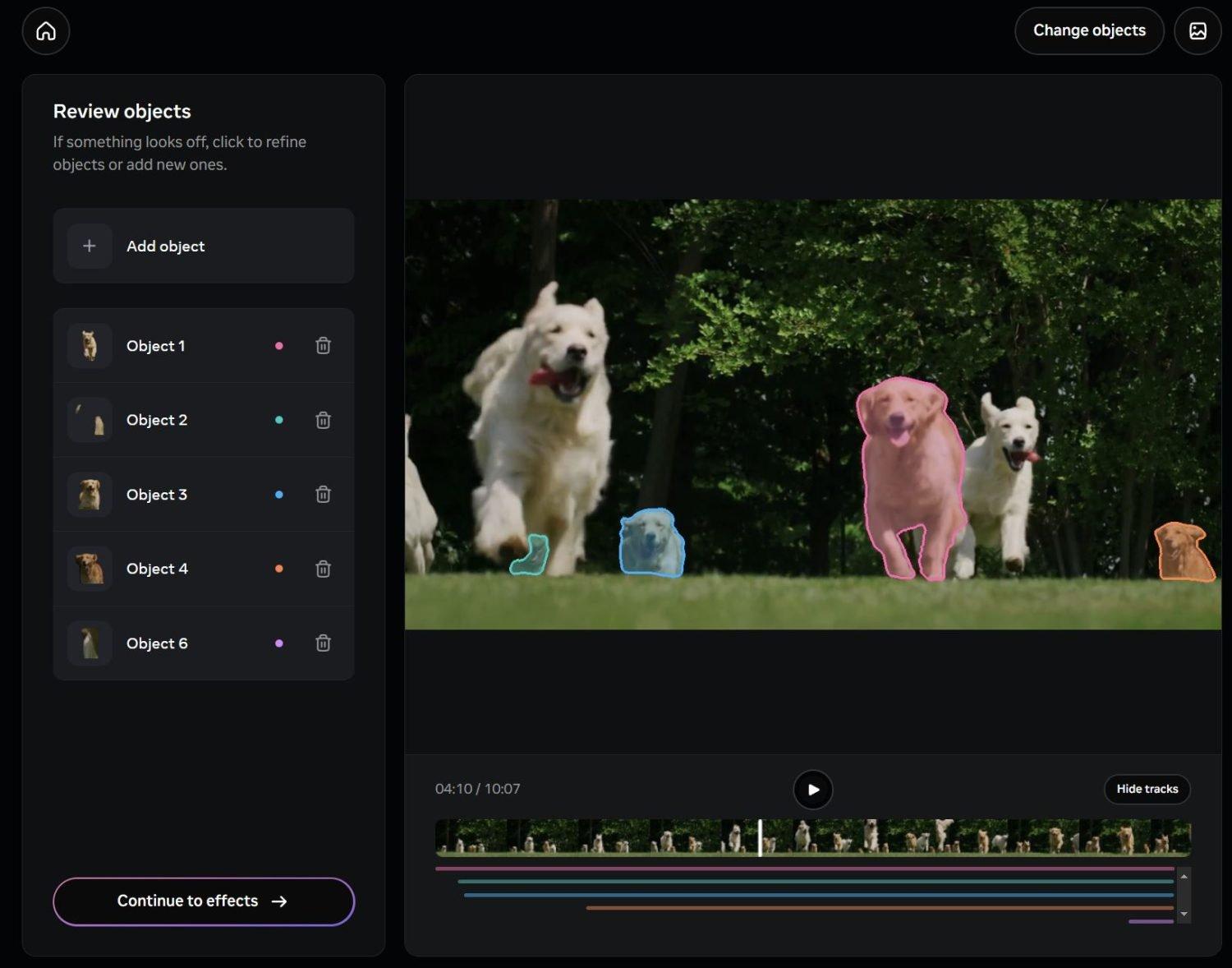
- SAM 3 introdueix segmentació d'imatges i de vídeo guiada per text i exemples visuals, amb un vocabulari de milions de conceptes.
- SAM 3D permet reconstruir objectes, escenes i cossos humans en 3D a partir d´una sola imatge, amb models oberts.
- Els models es poden provar sense coneixements tècnics a Segment Anything Playground, amb plantilles pràctiques i creatives.
- Meta allibera pesos, punts de control i nous benchmarks perquè desenvolupadors i investigadors d'Europa i la resta del món integrin aquestes capacitats als seus projectes.

Meta ha fet un nou pas en la seva aposta per la intel·ligència artificial aplicada a la visió per ordinador amb el llançament de SAM 3 i SAM 3D, dos models que amplien la família Segment Anything i que apunten a canviar la manera com treballem amb fotos i vídeos. Lluny de quedar-se en un experiment de laboratori, la companyia vol que aquestes eines siguin utilitzades tant per professionals com per usuaris sense perfil tècnic.
Amb aquesta nova generació, Meta se centra en millorar la detecció i la segmentació d'objectes ia apropar la reconstrucció tridimensional a un públic molt més ampli. Des de l'edició de vídeo fins a la visualització de productes per a comerç electrònic a Espanya i la resta d'Europa, la companyia planteja un escenari on descriure el que es vol fer amb paraules prou perquè la IA faci gran part del treball pesat.
Què aporta SAM 3 davant de versions anteriors
SAM 3 se situa com a evolució directa dels models de segmentació que Meta va presentar el 2023 i 2024, coneguts com a SAM 1 i SAM 2. Aquelles primeres versions se centraven a identificar quins píxels pertanyien a cada objecte, usant principalment indicacions visuals com a punts, caixes o màscares, i en el cas de SAM 2, seguint objecte.
La novetat clau ara és que SAM 3 entén prompts de text rics i precisos, no només etiquetes generals. Mentre que abans es treballava amb termes simples com “cotxe” o “autobús”, el nou model és capaç de respondre a descripcions molt més concretes, per exemple “autobús escolar groc” o “cotxe vermell aparcat a segona fila”.
A la pràctica, això significa que només cal escriure alguna cosa com “gorra vermella de beisbol” perquè el sistema localitzi i separi tots els elements que encaixen amb aquesta descripció dins d'una imatge o un vídeo. Aquesta capacitat d'afinar amb paraules és especialment útil en contextos professionals d'edició, publicitat o anàlisi de contingut, on sovint cal fixar-se en detalls molt concrets.
A més, SAM 3 s'ha dissenyat per integrar-se amb models de llenguatge multimodals de grans dimensions. Això permet anar més enllà de frases senzilles i utilitzar indicacions complexes del tipus: “persones assegudes però que no portin una gorra vermella” o “vianants que estiguin mirant cap a la càmera però sense motxilla”. Aquests tipus d'instruccions combinen condicions i exclusions que fins fa poc eren difícils de traslladar a una eina de visió per ordinador.
Rendiment i escala del model SAM 3

Meta també ha volgut destacar la part menys visible però crucial: el rendiment tècnic i l'escala de coneixement del model. Segons les dades de la companyia, SAM 3 és capaç de processar una sola imatge amb més de cent objectes detectats al voltant de 30 mil·lisegons usant una GPU H200, una velocitat molt propera al que es necessita per a fluxos de treball exigents.
En el cas del vídeo, la firma assegura que el sistema manté un rendiment pràcticament en temps real quan es treballa amb al voltant de cinc objectes simultanis, cosa que el fa viable per a tasques de seguiment i segmentació de contingut en moviment, des de clips curts per a xarxes socials fins a projectes de producció més ambiciosos.
Per aconseguir aquest comportament, Meta ha construït una base d'entrenament amb més de 4 milions de conceptes únics, combinant anotadors humans amb altres models de IA que ajuden a etiquetar grans volums de dades. Aquesta barreja de supervisió manual i automàtica busca equilibrar precisió i escala, cosa clau perquè el model respongui bé a indicacions variades en contextos europeus, llatinoamericans o altres mercats.
La companyia emmarca SAM 3 dins del que anomena Segment Anything Collection, una família de models, benchmarks i recursos dissenyada per anar ampliant la comprensió visual de la IA. El llançament s'acompanya d'un punt de referència nou per a la segmentació de “vocabulari obert”, enfocat a mesurar fins a quin punt el sistema és capaç d'entendre gairebé qualsevol concepte que s'expressi en llenguatge natural.
Integració a Edits, Vibes i altres eines de Meta

Més enllà del component tècnic, Meta ja ha començat a integrar SAM 3 en productes concrets que apunten a un ús quotidià. Una de les primeres destinacions serà Edits, la seva aplicació de creació i edició de vídeo, on la idea és que lusuari pugui seleccionar persones o objectes específics amb una simple descripció en text i aplicar efectes, filtres o canvis només a aquestes parts del metratge.
Una altra via d'integració es donarà a Vibes, dins de l'app Meta AI i de la plataforma meta.ai. En aquest entorn, la segmentació per text es combinarà amb eines generatives per crear noves experiències d'edició i creativitat, com ara fons personalitzats, efectes de moviment o modificacions selectives en fotos pensades per a xarxes socials molt populars a Espanya i la resta d'Europa.
El plantejament de la companyia és que aquestes capacitats no quedin restringides a estudis professionals, sinó que arribin a creadors independents, agències petites i usuaris avançats que treballen diàriament amb contingut visual. La possibilitat de segmentar escenes escrivint descripcions en llenguatge natural redueix la corba daprenentatge respecte a eines tradicionals basades en màscares manuals i capes.
Alhora, Meta manté un discurs d'obertura cap a desenvolupadors externs, apuntant que aplicacions de tercers -des d'eines d'edició fins a solucions per a anàlisi de vídeo en comerç minorista o seguretat- puguin recolzar-se a SAM 3 sempre que es respectin les polítiques d'ús de la companyia.
SAM 3D: reconstrucció tridimensional des d'una sola imatge

L'altra gran novetat és SAM 3D, un sistema pensat per realitzar reconstruccions tridimensionals a partir d'imatges en 2D. En lloc de necessitar múltiples captures des de diferents angles, el model aspira a generar una representació 3D fiable partint d'una foto única, especialment interessant per als que no disposen d'equips o fluxos d'escanejat especialitzats.
SAM 3D es compon de dos models de codi obert amb funcions diferenciades: Objectes 3D SAM, centrat a reconstruir objectes i escenes, i Cos 3D del SAM, orientat a estimar la forma i el cos humans. Aquesta separació permet adaptar el sistema a casos dús molt diferents, des de catàlegs de producte fins a aplicacions de salut o esport.
Segons Meta, SAM 3D Objects marca un nou llistó de rendiment en reconstrucció 3D guiada per IA, superant amb comoditat mètodes previs en mètriques clau de qualitat. Per poder avaluar els resultats de manera més rigorosa, la companyia ha treballat amb artistes en la creació de SAM 3D Artist Objects, un conjunt de dades específicament dissenyades per valorar la fidelitat i el detall de les reconstruccions en una gran varietat d'imatges i objectes.
Aquest avenç obre la porta a usos pràctics en àrees com la robòtica, la ciència, la medicina esportiva o la creativitat digital. Per exemple, en robòtica pot facilitar que els sistemes entenguin millor el volum dels objectes amb què interactuen; en investigació mèdica o esportiva, podria ajudar a analitzar la postura i el moviment del cos; i en disseny creatiu, serveix com a base per generar models 3D per a animació, videojocs o experiències immersives.
Una de les primeres aplicacions comercials ja visibles és la funció "Vista des de l'habitació" de Facebook Marketplace, que permet visualitzar com quedaria un moble o objecte de decoració en una habitació real abans de comprar-lo. Amb SAM 3D, Meta cerca perfeccionar aquest tipus d'experiències, molt rellevants per al comerç electrònic europeu, on la devolució de productes per expectatives no complertes suposa un cost creixent.
Segment Anything Playground: un entorn per experimentar
Perquè el públic pugui provar aquestes capacitats sense instal·lar res, Meta ha habilitat el Segmentar qualsevol cosa al parc infantil, una plataforma web que permet carregar imatges o vídeos i experimentar amb SAM 3 i SAM 3D directament des del navegador. La idea és que qualsevol persona amb curiositat per la IA visual pugui explorar què es pot fer sense coneixements de programació.
En el cas de SAM 3, el Playground permet segmentar objectes usant frases curtes o indicacions detallades, combinant text i, si es vol, exemples visuals. Això facilita tasques habituals com ara seleccionar persones, cotxes, animals o elements específics de l'escena i aplicar-los accions concretes, des d'efectes estètics fins a desenfocaments o substitució de fons.
Quan es treballa amb SAM 3D, la plataforma fa possible explorar escenes des de noves perspectives, reorganitzar objectes, aplicar efectes tridimensionals o generar vistes alternatives. Per als que es dediquen al disseny, la publicitat o el contingut 3D, suposa una manera ràpida de prototipar idees sense haver de passar per eines tècniques complexes des del primer minut.
El Playground també inclou una sèrie de plantillas listas para usar orientades a tasques molt concretes. Entre elles, opcions pràctiques com pixelar cares o matrícules per motius de privadesa, i efectes visuals com esteles de moviment, ressalts selectius o focus de llum sobre zones d'interès del vídeo. Aquest tipus de funcions poden encaixar especialment bé en fluxos de treball de mitjans digitals i creadors de contingut a Espanya, on la producció de vídeos curts i peces per a xarxes és constant.
Recursos oberts per a desenvolupadors i investigadors

En línia amb l'estratègia que Meta ha seguit en altres llançaments d'IA, la companyia ha decidit alliberar una part important dels recursos tècnics associats a SAM 3 i SAM 3D. Pel primer, s'han fet públics els pesos del model, un nou benchmark orientat a la segmentació de vocabulari obert i un document tècnic detallant-ne el desenvolupament.
En el cas de SAM 3D, estan disponibles els punts de control del model, codi d'inferència i un conjunt de dades d'avaluació de nova generació. Aquest dataset inclou una varietat considerable d'imatges i objectes que pretén anar més enllà dels punts de referència 3D tradicionals, aportant més realisme i complexitat, cosa que pot resultar molt útil per a grups de recerca europeus que treballen en visió per ordinador i gràfics.
Meta també ha anunciat col·laboracions amb plataformes d'anotació com Roboflow, per tal que desenvolupadors i empreses puguin anotar les seves pròpies dades i ajustar SAM 3 a necessitats específiques. Això obre la porta a solucions sectorials, des d'inspecció industrial fins a anàlisi de trànsit urbà, passant per projectes de patrimoni cultural en què sigui important segmentar amb precisió elements arquitectònics o artístics.
En apostar per un enfocament relativament obert, la companyia busca que l'ecosistema de desenvolupadors, universitats i startups -incloses les que operen a Espanya ia la resta d'Europa- pugui experimentar amb aquestes tecnologies, integrar-les en productes propis i, en última instància, aportar casos d'ús que vagin més enllà dels que Meta pot desenvolupar internament.
Amb SAM 3 i SAM 3D, Meta pretén consolidar una plataforma d'IA visual més flexible i accessible, en què la segmentació guiada per text i la reconstrucció 3D a partir d'una sola imatge deixin de ser capacitats reservades a equips altament especialitzats. L'impacte potencial s'estén des de l'edició de vídeo quotidiana fins a aplicacions avançades en ciència, indústria o comerç electrònic, en un context on la combinació de llenguatge, visió per ordinador i creativitat comença a ser una eina de treball habitual i no només una promesa tecnològica.
Sóc un apassionat de la tecnologia que ha convertit els seus interessos frikis en professió. Porto més de 10 anys de la meva vida utilitzant tecnologia d'avantguarda i traslladant tota mena de programes per pura curiositat. Ara he especialitzat en tecnologia d'ordinador i videojocs. Això és perquè des de fa més de 5 anys que treballo redactant per a diverses webs en matèria de tecnologia i videojocs, creant articles que busquen donar-te la informació que necessites amb un llenguatge comprensible per tothom.
Si tens qualsevol pregunta, els meus coneixements van des de tot allò relacionat amb el sistema operatiu Windows així com Android per a mòbils. I és que el meu compromís és amb tu, sempre estic disposat a dedicar-te uns minuts i ajudar-te a resoldre qualsevol dubte que tinguis a aquest món d'internet.