- Novo modelo especializado em programação com compactação para sessões longas sem perda de coerência.
- Melhorias mensuráveis em benchmarks (SWE-Bench, SWE-Lancer, Terminal-Bench) e uso de menos tokens.
- Disponível para Plus, Pro, Business, Edu e Enterprise; integração com as ferramentas Codex; API pública planejada.
- Ambiente isolado, sem rede por padrão, com controles de segurança e monitoramento.

A OpenAI lançou o GPT-5.1-Codex-Max., um novo modelo de inteligência artificial voltado para o desenvolvimento de software que vem com o prometer manter o rumo em projetos de longo prazo sem perder o contexto.Na prática, estamos falando de um evolução do Codex capaz de realizar tarefas complexas por horas, com melhorias em eficiência e velocidade que são perceptíveis em fluxos de trabalho reais.
A grande novidade reside na sua capacidade de raciocinar de forma sustentada graças a uma técnica de gerenciamento de memória chamada compactaçãoEssa abordagem permite que a janela de contexto seja saturada antes de ficar sobrecarregada. O sistema identifica redundâncias, resume os acessórios e retém o essencial.evitando assim os descuidos típicos que atrasam tarefas de longo prazo.
O que é GPT-5.1-Codex-Max?

É um modelo específico para programação otimizado para tarefas ampliadas de engenharia de softwareDesde a revisão de código até a geração de pull requests e o suporte ao desenvolvimento frontend. Ao contrário das gerações anteriores, é treinados para manter a consistência durante longas jornadas de trabalho e em repositórios de tamanho considerável.
A OpenAI coloca o GPT-5.1-Codex-Max um passo à frente do Codex. permitindo fluxos contínuos de 24 horas ou mais sem degradação dos resultadosPara quem desenvolve produtos, isso significa menos interrupções devido a limitações de contexto e menos tempo perdido explicando novamente as tarefas em iterações sucessivas.
Inovações técnicas e a técnica de compactação
A chave está em compactação históricaO modelo identifica quais partes do contexto são literalmente dispensáveis, resume-as e retém referências críticas para continuar a tarefa sem sobrecarregar a memória. Esse mecanismo também é chamado de "compressão" em alguns materiais, mas descreve o mesmo processo de filtragem inteligente do contexto.
Com essa base, o GPT-5.1-Codex-Max pode continuar iterando sobre o código. Corrigir erros e refatorar Módulos inteiros podem ser executados sem que a janela de contexto se torne um gargalo. Em casos de uso intensivo, isso também reduz o número de tokens necessários para o processamento, impactando tanto o custo quanto a latência.
O modelo incorpora um modo de Raciocínio “extremamente elevado” Para problemas complexos, com o objetivo de aprofundar a análise quando a tarefa o exigir, mantendo a consistência dos resultados em processos com muitas etapas e dependências.
Desempenho e benchmarks: o que os números dizem
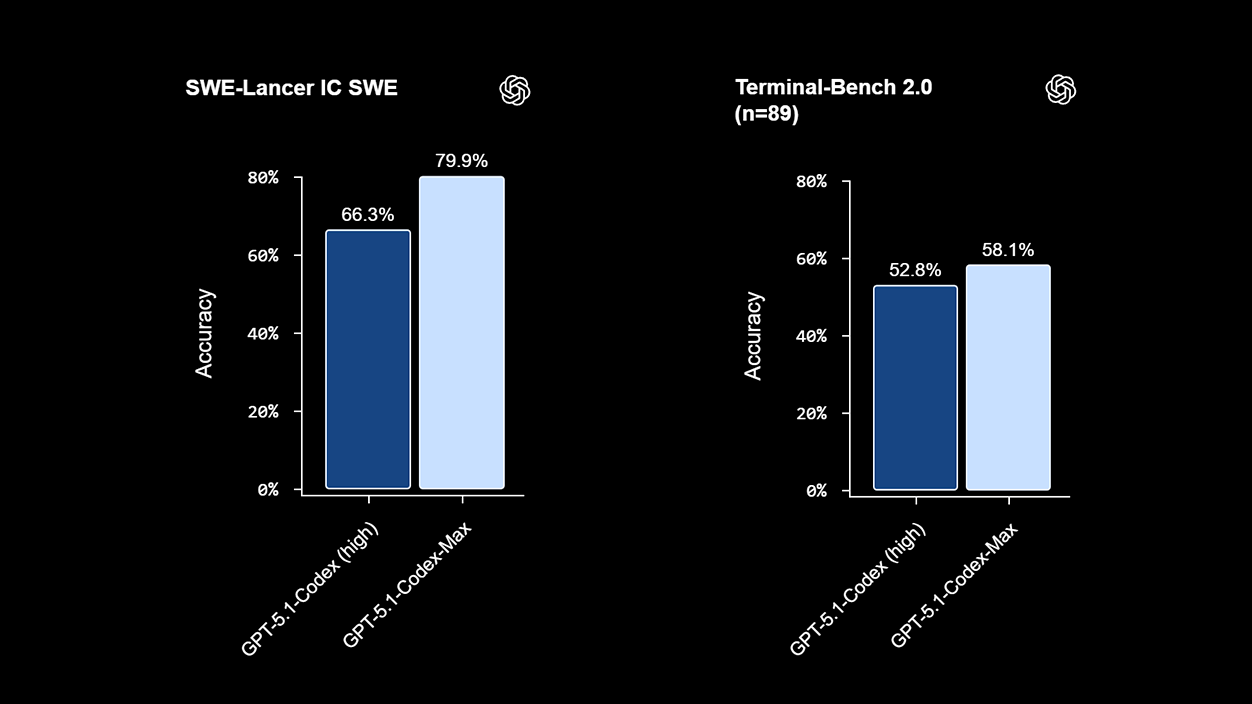
Em avaliações internas focadas em programação, O GPT-5.1-Codex-Max é uma melhoria em relação ao seu antecessor. em diferentes frentes, com taxas de sucesso mais elevadas e maior eficiência dos tokensEsses resultados, divulgados pela OpenAI, Eles refletem testes em tarefas de engenharia do mundo real e baterias como SWE-Bench Verified, SWE-Lancer IC SWE e Terminal-Bench 2.0..
Entre os dados compartilhados, o modelo atinge aproximadamente 77,9% verificado pelo SWE-Bench (em comparação com 73,7% do GPT-5.1-Codex), registra 79,9% em SWE-Lancer IC SWE e alcançar 58,1% no Terminal-Bench 2.0Além disso, em contextos prolongados, foram medidos aumentos de velocidade de 27% a 42% em tarefas típicas em comparação com o Codex, de acordo com as mesmas fontes.
Em comparações publicadas com outros modelos, como Gemini 3 ProA OpenAI pretende obter uma ligeira vantagem em vários testes de desempenho de programação, e incluindo paridade em testes competitivos como o LiveCodeBench ProÉ importante ter em mente que esses números provêm de medidas internas e podem variar em ambientes de produção.
Integrações, ferramentas e disponibilidade em Espanha e na Europa.
O GPT-5.1-Codex-Max já está operacional em superfícies baseadas em CódiceOs serviços oficiais de CLI, extensões de IDE e revisão de código de Ecossistema OpenAIA empresa indica que o acesso público à API estará disponível em uma fase posterior, permitindo que as equipes comecem a testá-la hoje mesmo. ferramentas nativas enquanto preparam integrações personalizadas.
Em relação à disponibilidade comercial, os planos ChatGPT Plus, Pro, Business, Edu e Enterprise Isso inclui o novo modelo desde o seu lançamento. Usuários e organizações na Espanha e no resto do mundo. União Europeia Com essas assinaturas, você pode ativá-lo em seus fluxos, sem a necessidade de implantações adicionais, desde que utilize as superfícies compatíveis com o Codex.
A OpenAI também observa que o modelo está otimizado para funcionar em ambientes Windows, ampliando o escopo para além do Unix e facilitando sua adoção em empresas com parques de desenvolvimento mistos e ferramentas corporativas padronizadas.
Controles de segurança operacional e de risco
Para reduzir o risco em execuções de longa duração, o modelo opera em um espaço de trabalho isoladosem permissão para escrever fora do seu escopo padrão. Além disso, a conectividade de rede é desativada, a menos que seja explicitamente habilitada pelo desenvolvedor responsável, reforçando a privacidade.
O ambiente incorpora mecanismos de monitoramento que detectam atividades anômalas e interrompem processos caso haja suspeita de uso indevido. Essa configuração busca equilibrar a autonomia do agente com medidas de segurança razoáveis para equipes que gerenciam código sensível ou repositórios críticos.
Casos de uso em que mais contribui

A principal vantagem se manifesta em trabalhos que exigem memória persistente e continuidade: Refatoração extensiva, depuração que exige monitoramento prolongado, revisões de código contínuas e automação de solicitações de pull em grandes repositórios.Nessas tarefas, a compactação reduz o "desgaste" do contexto e mantém a coerência.
Para startups e equipes técnicas, Delegar esses processos a um modelo estável permite maior foco em prioridades do produtoPara acelerar as entregas e reduzir erros resultantes de fadiga ou repetição manual. Tudo isso, com um consumo de tokens mais simplificado do que nas versões anteriores.
- Projetos com múltiplos módulos onde a continuidade entre as sessões é crucial.
- CI/CD assistida com verificações e correções que avançam em segundo plano.
- Suporte de front-end e revisões entre contextos. em histórias de usuário complexas.
- Análise de falhas e depuração duradouro Sem precisar reexplicar o caso a cada poucas horas.
Diferenças em comparação com o Codex e outros modelos.
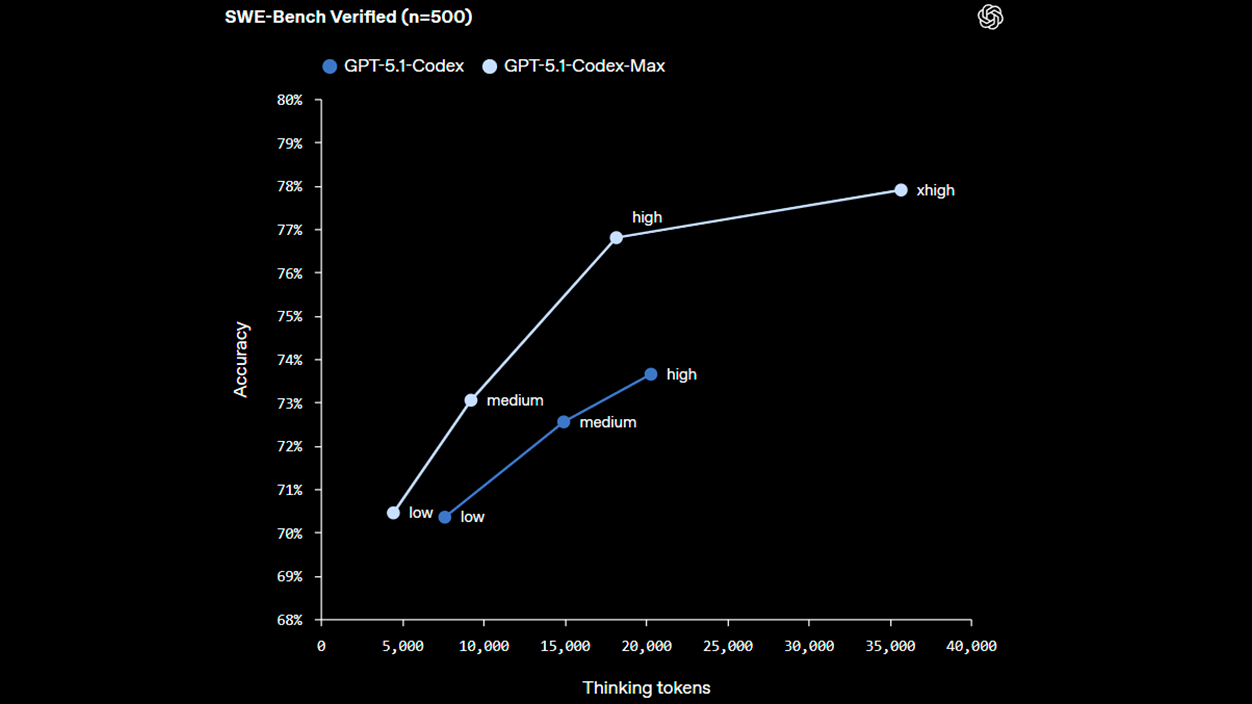
A principal diferença em relação ao Codex clássico reside não apenas no poder bruto, mas também na gestão de contexto eficaz A longo prazo, o Codex se destacava em tarefas específicas; o Codex-Max foi projetado para processos contínuos, onde o modelo atua como um colaborador que não se perde com o passar das horas.
Comparações com alternativas como Gemini 3 Pro Eles demonstram preferência pelo GPT-5.1-Codex-Max em diversos testes de codificação. De acordo com os dados divulgados, embora O mais prudente é validar esses resultados em nossos próprios ambientes e com cargas de trabalho reais. antes de padronizá-lo no fluxo de trabalho de uma organização.
Qualquer pessoa que precise de uma IA orientada a código, capaz de suportar maratonas técnicas sem se cansar, encontrará em GPT-5.1-Codex-Max Uma opção especificamente voltada para continuidade, segurança por padrão e eficiência de tokens.; um conjunto de qualidades que, em equipes na Espanha e na Europa com ritmos exigentes, podem se traduzir em entregas mais rápidas e manutenção de código mais refinada.

Sou um entusiasta da tecnologia que transformou seus interesses “geek” em profissão. Passei mais de 10 anos da minha vida usando tecnologia de ponta e mexendo em todos os tipos de programas por pura curiosidade. Agora me especializei em informática e videogames. Isto porque há mais de 5 anos escrevo para diversos sites sobre tecnologia e videojogos, criando artigos que procuram dar-lhe a informação que necessita numa linguagem compreensível para todos.
Se você tiver alguma dúvida, meu conhecimento vai desde tudo relacionado ao sistema operacional Windows até Android para celulares. E meu compromisso é com você, estou sempre disposto a dedicar alguns minutos e te ajudar a resolver qualquer dúvida que você possa ter nesse mundo da internet.