- Escolha em etapas: primeiro, engenharia rápida, depois, ajuste rápido e, se necessário, ajuste fino.
- O RAG aumenta as respostas com recuperação semântica; o prompt correto previne alucinações.
- A qualidade dos dados e a avaliação contínua são mais importantes do que qualquer truque isolado.
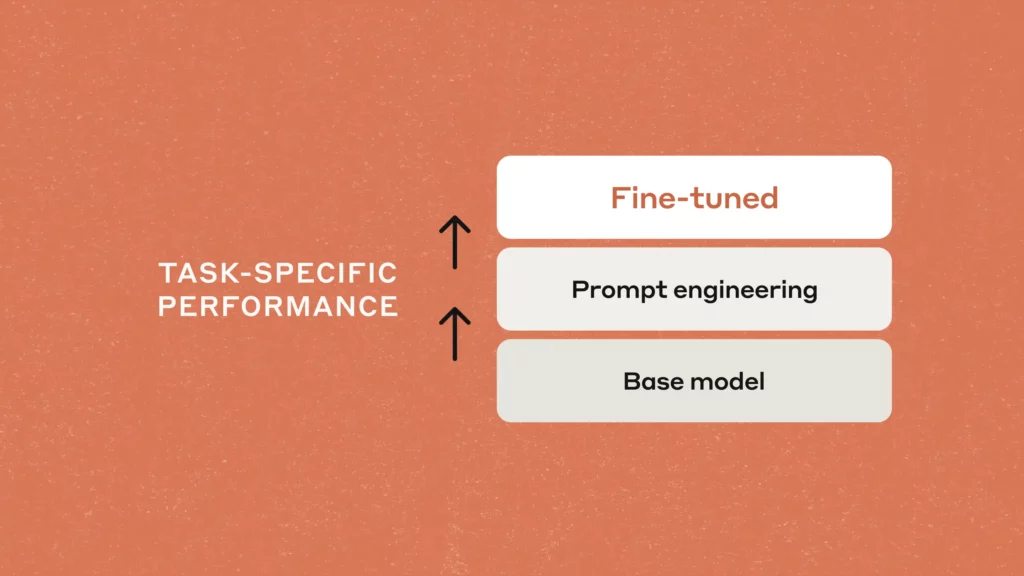
A fronteira entre O que você consegue com bons prompts e o que você consegue ajustando um modelo É mais sutil do que parece, mas entendê-lo faz a diferença entre respostas medíocres e sistemas realmente úteis. Neste guia, mostrarei, com exemplos e comparações, como escolher e combinar cada técnica para alcançar resultados sólidos em projetos do mundo real.
O objetivo não é ficar na teoria, mas colocá-la em prática no dia a dia: quando a engenharia rápida ou o ajuste rápido forem suficientes para você, Quando vale a pena investir em ajustes finos?, como tudo isso se encaixa nos fluxos do RAG e quais práticas recomendadas reduzem custos, aceleram iterações e evitam becos sem saída.
O que são engenharia rápida, ajuste rápido e ajuste fino?
Antes de continuar, vamos esclarecer alguns conceitos:
- Engenharia rápida é a arte de projetar instruções claras com contexto e expectativas bem definidos. para guiar um modelo já treinado. Em um chatbot, por exemplo, define a função, o tom, o formato de saída e os exemplos para reduzir a ambiguidade e melhorar a precisão sem afetar os pesos do modelo.
- O ajuste fino modifica os parâmetros internos de um modelo pré-treinado com dados adicionais do domínio. para aprimorar seu desempenho em tarefas específicas. É ideal quando você precisa de terminologia especializada, decisões complexas ou máxima precisão em áreas sensíveis (saúde, jurídico, financeiro).
- O ajuste rápido adiciona vetores treináveis (prompts suaves) que o modelo interpreta junto com o texto de entradaEle não retreina o modelo inteiro: ele congela seus pesos e otimiza apenas as "trilhas" incorporadas. É um meio-termo eficiente quando você quer adaptar o comportamento sem o custo de um ajuste fino completo.
No design de UX/UI, a engenharia de prompts melhora a clareza da interação humano-computador (o que espero e como solicito), enquanto o ajuste fino aumenta a relevância e a consistência do resultado. Combinados, permitir interfaces mais úteis, rápidas e confiáveis.
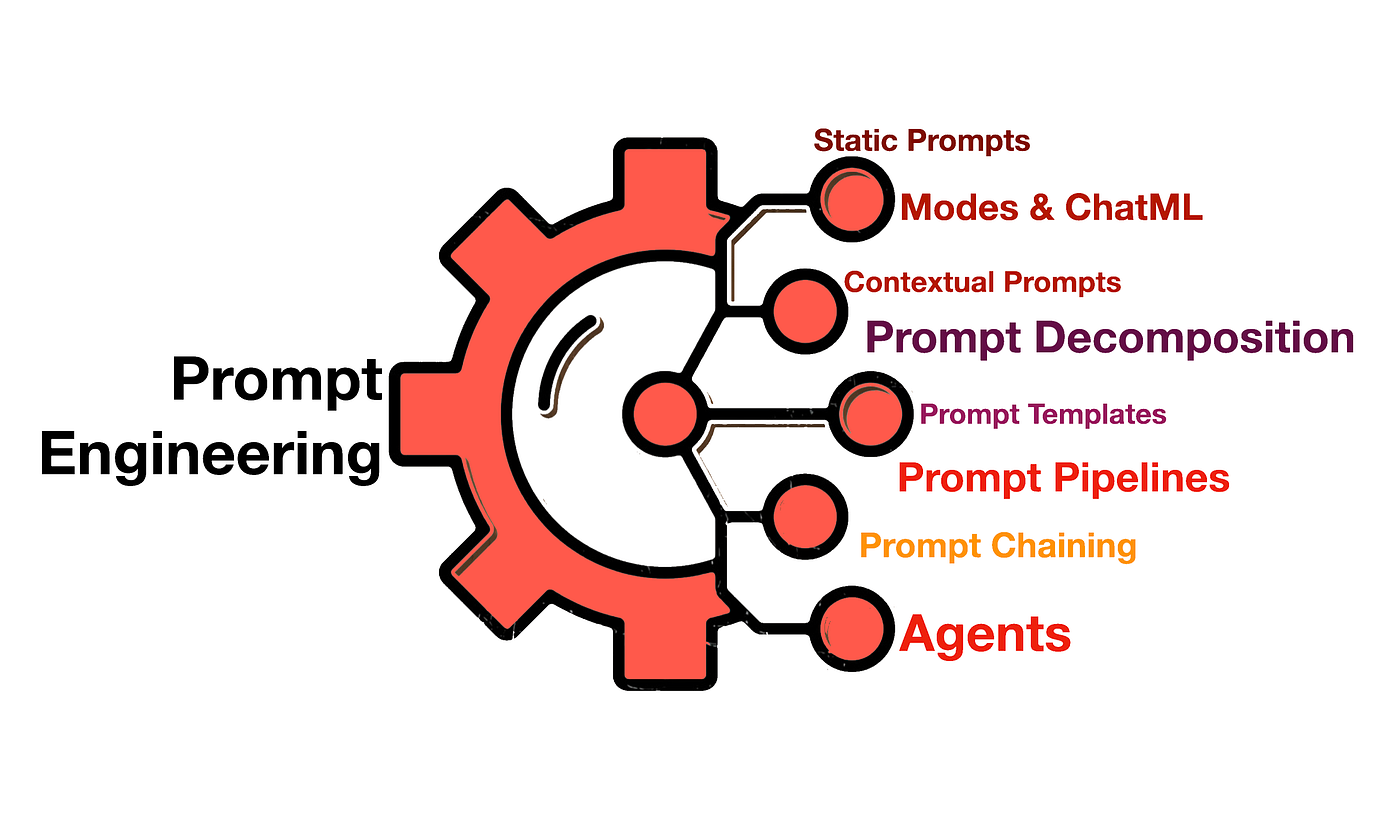
Engenharia rápida em profundidade: técnicas que movem a agulha
Engenharia rápida não se trata de testes cegos. Há métodos sistemáticos que melhoram a qualidade sem afetar o modelo ou seus dados base:
- Poucos tiros vs tiro zero. em poucos tiros Você adiciona alguns exemplos bem escolhidos para que o modelo capture o padrão exato; em tiro zero Você confia em instruções claras e taxonomias sem exemplos.
- Manifestações em contextoDemonstre o formato esperado (entrada → saída) com minipares. Isso reduz erros de formatação e alinha as expectativas, especialmente se você precisar de campos, rótulos ou estilos específicos na resposta.
- Modelos e variáveisDefina prompts com espaços reservados para alterar dados. Prompts dinâmicos são essenciais quando a estrutura de entrada varia, por exemplo, na limpeza ou extração de dados de formulários, onde cada registro chega em um formato diferente.
- VerbalizadoresEles são "tradutores" entre o espaço textual do modelo e suas categorias de negócios (por exemplo, mapeando "feliz" → "positivo"). Escolher bons verbalizadores melhora a precisão e a consistência dos rótulos, especialmente na análise de sentimentos e na classificação temática.
- Sequências de caracteres de prompt (encadeamento de prompts). Divida uma tarefa complexa em etapas: resumir → extrair métricas → analisar sentimentos. Encadear etapas torna o sistema mais depurável e robusto, e frequentemente melhora a qualidade em comparação a "solicitar tudo de uma vez".
- Boas práticas de formatação: marca funções (“Você é um analista…”), define o estilo (“responda em tabelas/JSON”), estabelece critérios de avaliação (“penaliza alucinações, cita fontes quando existem”) e explica o que fazer em caso de incerteza (por exemplo, “se houver dados faltando, indique 'desconhecido'”).
Componentes de ajuste rápido
Além dos prompts naturais, o ajuste de prompts incorpora prompts suaves (embeddings treináveis) que precedem a entrada. Durante o treinamento, o gradiente ajusta esses vetores para aproximar a saída do alvo. sem afetar os outros pesos do modelo. É útil quando se busca portabilidade e baixo custo.
Você carrega o LLM (por exemplo, um GPT‑2 ou similar), prepara seus exemplos e você prepara os prompts suaves para cada entradaVocê treina apenas esses embeddings, para que o modelo “veja” um prefácio otimizado que orienta seu comportamento na sua tarefa.
Aplicação prática:Em um chatbot de atendimento ao cliente, você pode incluir padrões típicos de perguntas e o tom de resposta ideal em prompts suaves. Isso acelera a adaptação sem manter diferentes ramos de modelos. nem consumir mais GPU.
Ajuste fino aprofundado: quando, como e com que cautela
O ajuste fino retreina (parcial ou completamente) os pesos de um LLM com um conjunto de dados de destino. para especializá-la. Esta é a melhor abordagem quando a tarefa se desvia do que o modelo viu durante o pré-treinamento ou requer terminologia e decisões mais refinadas.
Você não começa do zero: modelos ajustados para bate-papo, como gpt-3.5-turbo Eles já estão ajustados para seguir instruções. Seu ajuste fino “responde” a esse comportamento, que pode ser sutil e incerto, por isso é uma boa ideia experimentar o design de prompts e entradas do sistema.
Algumas plataformas permitem que você encadeie uma melodia fina sobre uma já existente. Isso fortalece sinais úteis a um custo menor. para retreinar do zero e facilita iterações guiadas por validação.
Técnicas eficientes como LoRA inserem matrizes de baixa classificação para adaptar o modelo com poucos parâmetros novos. Vantagem: menor consumo, implementações ágeis e reversibilidade (você pode “remover” a adaptação sem tocar na base).
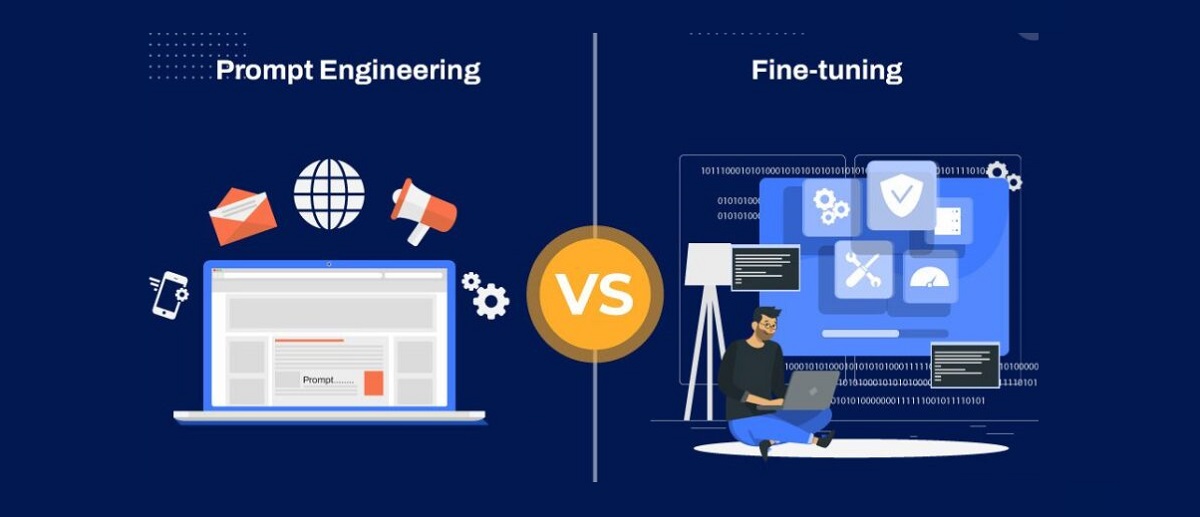
Comparação: ajuste rápido vs ajuste fino
- ProcessoO ajuste fino atualiza os pesos do modelo com um conjunto de dados de destino rotulado; o ajuste rápido congela o modelo e ajusta apenas as incorporações treináveis que são concatenadas à entrada; a engenharia rápida otimiza o texto de instruções e os exemplos não treinados.
- Ajuste de ParámetrosNo ajuste fino, você modifica a rede; no ajuste rápido, você apenas toca nos "prompts suaves". Na engenharia rápida, não há ajuste paramétrico, apenas design.
- Formato de entradaO ajuste fino geralmente respeita o formato original; o ajuste rápido reformula a entrada com incorporações e modelos; a engenharia rápida aproveita a linguagem natural estruturada (funções, restrições, exemplos).
- RecursosO ajuste fino é mais caro (computação, dados e tempo); o ajuste rápido é mais eficiente; a engenharia rápida é a mais barata e rápida para iterar, se o caso permitir.
- Objetivo e riscosO ajuste fino otimiza diretamente a tarefa, eliminando o risco de overfitting; o ajuste rápido se alinha com o que já foi aprendido no LLM; a engenharia rápida atenua alucinações e erros de formatação com as melhores práticas sem afetar o modelo.
Dados e ferramentas: o combustível do desempenho
- Qualidade dos dados em primeiro lugar: cura, desduplicação, balanceamento, cobertura de casos extremos e metadados ricos Eles representam 80% do resultado, não importa se você faz ajustes finos ou rápidos.
- Automatizar pipelines: plataformas de engenharia de dados para IA generativa (por exemplo, soluções que criam produtos de dados reutilizáveis) ajudar a integrar, transformar, entregar e monitorar conjuntos de dados para treinamento e avaliação. Conceitos como “Nexsets” ilustram como empacotar dados prontos para consumo do modelo.
- Ciclo de feedback: Colete sinais de uso do mundo real (sucessos, erros, perguntas frequentes) e insira-os em seus prompts, prompts suaves ou conjuntos de dados. É a maneira mais rápida de obter precisão.
- Reprodutibilidade: Prompts de versões, prompts flexíveis, dados e pesos personalizados. Sem rastreabilidade, é impossível saber o que mudou no desempenho ou retornar a um bom estado se uma iteração falhar.
- GeneralizaçãoAo expandir tarefas ou idiomas, certifique-se de que seus verbalizadores, exemplos e rótulos não sejam excessivamente adaptados a um domínio específico. Se você estiver mudando de área, talvez precise fazer alguns ajustes leves ou usar novos prompts suaves.
- E se eu alterar o prompt após o ajuste fino? Em geral, sim: o modelo deve inferir estilos e comportamentos a partir do que aprendeu, não apenas repetir tokens. É exatamente esse o objetivo de um mecanismo de inferência.
- Feche o ciclo com métricasAlém da precisão, ele mede a formatação correta, a cobertura, a citação da fonte no RAG e a satisfação do usuário. O que não é medido não melhora.
Escolher entre prompts, ajuste de prompts e ajuste fino não é uma questão de dogma, mas de contexto.: custos, prazos, risco de erro, disponibilidade de dados e necessidade de expertise. Se você dominar esses fatores, a tecnologia trabalhará a seu favor, e não o contrário.
Editor especializado em temas de tecnologia e internet com mais de dez anos de experiência em diferentes mídias digitais. Já trabalhei como editor e criador de conteúdo para empresas de e-commerce, comunicação, marketing online e publicidade. Também escrevi em sites de economia, finanças e outros setores. Meu trabalho também é minha paixão. Agora, através dos meus artigos em Tecnobits, procuro explorar todas as novidades e novas oportunidades que o mundo da tecnologia nos oferece todos os dias para melhorar nossas vidas.