- 微软推出Phi-4-multimodal,一种可同时处理语音、图像和文本的人工智能模型。
- 它拥有 5.600 亿个参数,在语音和视觉识别方面的表现优于更大的模型。
- 包括 Phi-4-mini,一个专注于文字处理任务的版本。
- 可在 Azure AI Foundry、Hugging Face 和 NVIDIA 上使用,在商业和教育领域有广泛的应用。

微软凭借多模态 Phi-4 在语言模型领域迈出了一步,其最新、最先进的人工智能能够同时处理文本、图像和语音。该模型与 Phi-4-mini 一起代表了 小型机型容量的演变 (SLM),无需大量参数即可提供效率和准确性。
Phi-4-multimodal的到来,不仅代表着微软技术的进步,也 它直接与谷歌和 Anthropic 等公司的大型模型竞争。其优化的架构和先进的推理能力使其 适用于多种应用的有吸引力的选择,从机器翻译到图像和语音识别。
什么是 Phi-4-multimodal 以及它是如何工作的?

Phi-4-multimodal是微软开发的可以同时处理文本、图像和语音的AI模型。与采用单一模式的传统模型不同,这种人工智能通过使用交叉学习技术将各种信息源集成到单一表示空间中。
该模型建立在以下架构上: 5.600亿个参数,使用一种称为 LoRA(低秩自适应)的技术来合并不同类型的数据。这使得语言处理更加精确,对上下文的解释更加深入。
主要功能和优势
Phi-4-multimodal在几项需要高水平人工智能的关键任务上特别有效:
- 语音识别: 它在转录和机器翻译测试中的表现优于 WhisperV3 等专门的模型。
- 图像处理: 它能够非常准确地解释文档、图形并执行 OCR。
- 低延迟推理: 这使得它可以在移动和低功耗设备上运行而不会牺牲性能。
- 模式之间的无缝集成: 他们理解文本、语音和图像的能力提高了他们的语境推理能力。
与其他型号的比较
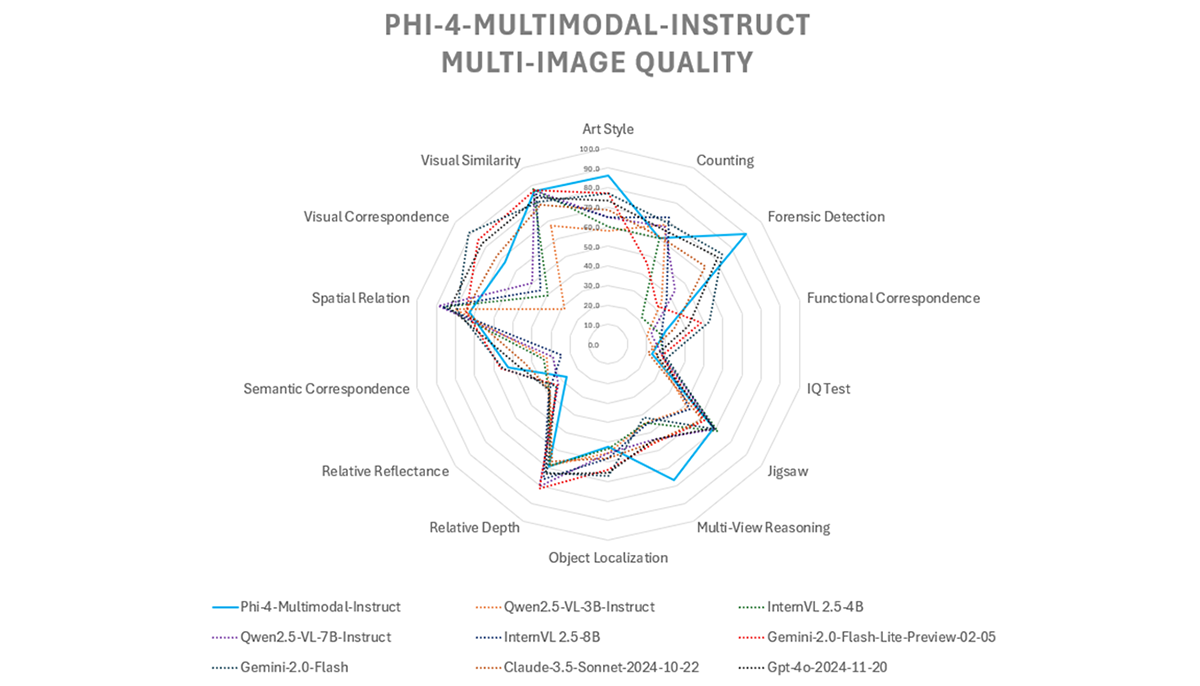
在性能方面,Phi-4-multimodal已被证明与更大的模型相当。 与 Gemini-2-Flash-lite 和 Claude-3.5-Sonnet 相比,在多模式任务中取得了类似的结果,同时由于其紧凑的设计保持了卓越的效率。
然而, 在语音问答方面存在一定的局限性其中 GPT-4o 和 Gemini-2.0-Flash 等模型具有优势。这是因为它的模型尺寸较小, 影响事实知识的保留。微软表示正在努力在未来版本中改进此功能。
Phi-4-mini:Phi-4-multimodal 的小兄弟
除了 Phi-4-multimodal,微软还推出了 Phi-4-迷你,针对特定基于文本的任务而优化的变体。该模型旨在提供 自然语言处理效率高,使其成为聊天机器人、虚拟助手和其他需要准确理解和生成文本的应用程序的理想选择。
可用性和应用

微软通过以下方式向开发人员提供 Phi-4-multimodal 和 Phi-4-mini: Azure AI Foundry、Hugging Face 和 NVIDIA API 目录。这意味着任何有权访问这些平台的公司或用户都可以开始试验该模型并将其应用于不同的场景。
鉴于其多模式方法,Phi-4 针对以下领域:
- 机器翻译和实时字幕。
- 面向企业的文档识别和分析。
- 带有智能助手的移动应用程序。
- 改善基于人工智能的教学的教育模式。
微软已经给出了 通过关注效率和可扩展性,对这些模型进行了有趣的改进。随着小型语言模型(SLM)领域的竞争日益激烈, Phi-4-multimodal 是大型模型的可行替代方案,在性能和处理能力之间实现平衡 即使在性能较差的设备上也可以访问.
我是一名技术爱好者,已将自己的“极客”兴趣变成了职业。出于纯粹的好奇心,我花了 10 多年的时间使用尖端技术并修改各种程序。现在我专攻计算机技术和视频游戏。这是因为 5 年多来,我一直在为各种技术和视频游戏网站撰写文章,旨在以每个人都能理解的语言为您提供所需的信息。
如果您有任何疑问,我的知识范围涵盖与 Windows 操作系统以及手机 Android 相关的所有内容。我对您的承诺是,我总是愿意花几分钟帮助您解决在这个互联网世界中可能遇到的任何问题。