- El throttling invisible aparece en CPU, hardware, red y herramientas, reduciendo el rendimiento sin errores claros.
- En Kubernetes, los límites de CPU y el CFS pueden estrangular contenedores y multiplicar la latencia si se configuran mal.
- El throttling térmico y el rate limiting en WAF protegen hardware y servicios, pero generan lentitud si no se entienden.
- Monitorizar métricas específicas y revisar políticas de límite es clave para ajustar rendimiento, seguridad y estabilidad.

Cuando hablamos de throttling o limitación del rendimiento, muchos piensan solo en errores, cuelgues o mensajes de alarma claros. Pero la realidad es mucho más sutil: tu aplicación, tu servidor o incluso tu móvil puede ir cada vez más lento sin que aparentemente pase nada raro en los gráficos ni en los sensores habituales, y sin que el sistema te avise de forma directa. Es el llamado throttling invisible.
Este tipo de comportamientos no siempre se deben a un bug en el código o a una mala arquitectura, sino a diferentes mecanismos de control de recursos y protección frente a sobrecargas que actúan “por detrás”: límites de CPU en Kubernetes, protección térmica en smartphones y portátiles, rate limiting en APIs o WAF, o incluso configuraciones de auditoría y herramientas como Lighthouse que simulan redes lentas. Entender cómo funcionan todos estos tipos de throttling es clave para no volverse loco buscando cuellos de botella donde no están.
Qué es el throttling invisible y por qué puede destrozar el rendimiento sin dar la cara
El término throttling hace referencia, en general, a cualquier técnica que reduce de forma deliberada el ritmo de procesamiento de un sistema para proteger la estabilidad, la seguridad o la integridad del hardware. Se vuelve “invisible” cuando, desde el punto de vista del usuario o incluso de parte de la monitorización, no aparecen señales obvias: no ves errores, el sistema no se apaga, la CPU parece ir “bien” y, sin embargo, todo responde más lento de lo normal.
Este fenómeno aparece en varios niveles: a nivel de infraestructura y kernel (CPU throttling con CFS y cgroups), a nivel de hardware (throttling térmico en procesadores de portátil o smartphone), a nivel de red y aplicación (rate limiting y control de peticiones HTTP en APIs y WAF) o en herramientas de análisis de rendimiento, donde se aplican perfiles de red simulada que limitan el ancho de banda y la latencia.
Lo que todas estas variantes comparten es que se basan en algún tipo de política de límite: de CPU, temperatura, tráfico o seguridad. Cuando se supera ese umbral, el sistema no “rompe”, sino que se protege reduciendo su velocidad. Desde el punto de vista de quien desarrolla o administra, esto se vive muchas veces como un rendimiento pésimo que cuesta relacionar con el origen real del problema.

CPU throttling en Kubernetes: el enemigo silencioso de los contenedores
En entornos con Kubernetes, el caso más típico de throttling invisible es el estrangulamiento de CPU producido por los límites configurados en los contenedores. En desarrollo local todo va como un tiro, pero cuando se despliega en el clúster de producción, los mismos procesos tardan el doble o el triple y nadie entiende por qué, ya que la aplicación no lanza errores y, a simple vista, la infraestructura aguanta.
El núcleo del problema está en cómo Linux, mediante los cgroups y el Completely Fair Scheduler (CFS), interpreta los resources.limits.cpu que se definen en los pods. Kubernetes traduce esos límites a dos parámetros internos: cpu.cfs_period_us, que marca el intervalo de tiempo en microsegundos sobre el que se mide el uso de CPU (normalmente 100.000 µs, es decir, 100 ms), y cpu.cfs_quota_us, que indica cuántos microsegundos de CPU está autorizado a consumir el contenedor dentro de cada periodo.
Por ejemplo, si a un contenedor le asignas un límite de 500m (medio core), Kubernetes terminará configurando un cpu.cfs_quota_us de unos 50.000 µs sobre un periodo de 100.000 µs. En la práctica, eso significa que el proceso puede ejecutar cómputo intensivo durante 50 ms y, al agotarlos, el kernel lo deja esperando hasta que arranca el siguiente periodo. Desde tu aplicación verás que una operación que podría hacerse en 100 ms se alarga a múltiples periodos, generando latencias que no se parecen en nada a lo que ves en local.
La cuestión se complica con la dualidad resources.requests.cpu frente a resources.limits.cpu. Mientras las peticiones de CPU ayudan al scheduler de Kubernetes a decidir en qué nodo colocar el pod, son los límites los que determinan cuándo entra en juego el throttling. Si ajustas mal estos parámetros —por ejemplo, con límites demasiado bajos o sin dar margen a picos de actividad—, tu contenedor pasará buena parte de su vida “parado” por decisión del kernel, aunque desde fuera parezca que la CPU ni siquiera está al 100%.
Este tipo de estrangulamiento es traicionero porque puede no provocar fallos críticos, sino algo mucho peor para la percepción de calidad: respuestas lentas, colas acumuladas y sensación de que el sistema está siempre un poco “atascado”. La herramienta de monitorización puede mostrar que la CPU no está saturada a nivel global del nodo, mientras que a nivel de cgroup el contenedor vive topándose constantemente con el techo que le has puesto.
Tipos de cargas de trabajo y cómo les afecta el CPU throttling
El impacto del throttling no es el mismo para todas las cargas. En el caso de APIs web y servicios sensibles a la latencia, cualquier retraso provocado por quedarse sin cuota de CPU se traduce en tiempos de respuesta mucho peores, timeouts en clientes, y una experiencia a trompicones. Aquí, establecer límites demasiado ajustados puede salir muy caro.
Para trabajos por lotes (batch), en cambio, el estrangulamiento puede ser una herramienta perfectamente válida: permites que los procesos de segundo plano no “se coman” la máquina y das prioridad práctica a los servicios interactivos. Es asumible que un job de análisis tarde algo más si con ello garantizas que la parte de cara al usuario se mantiene fluida.
Entre las causas más frecuentes de problemas graves de rendimiento por throttling destacan los límites de CPU mal dimensionados, los servicios con patrones de carga a ráfagas (que alcanzan el techo muy deprisa) y las fases de arranque de aplicaciones que consumen mucha CPU en poco tiempo. Este último caso es especialmente molesto: tu servicio tarda una eternidad en levantar en producción porque justo en el momento donde más necesita CPU, el sistema empieza a estrangularlo.
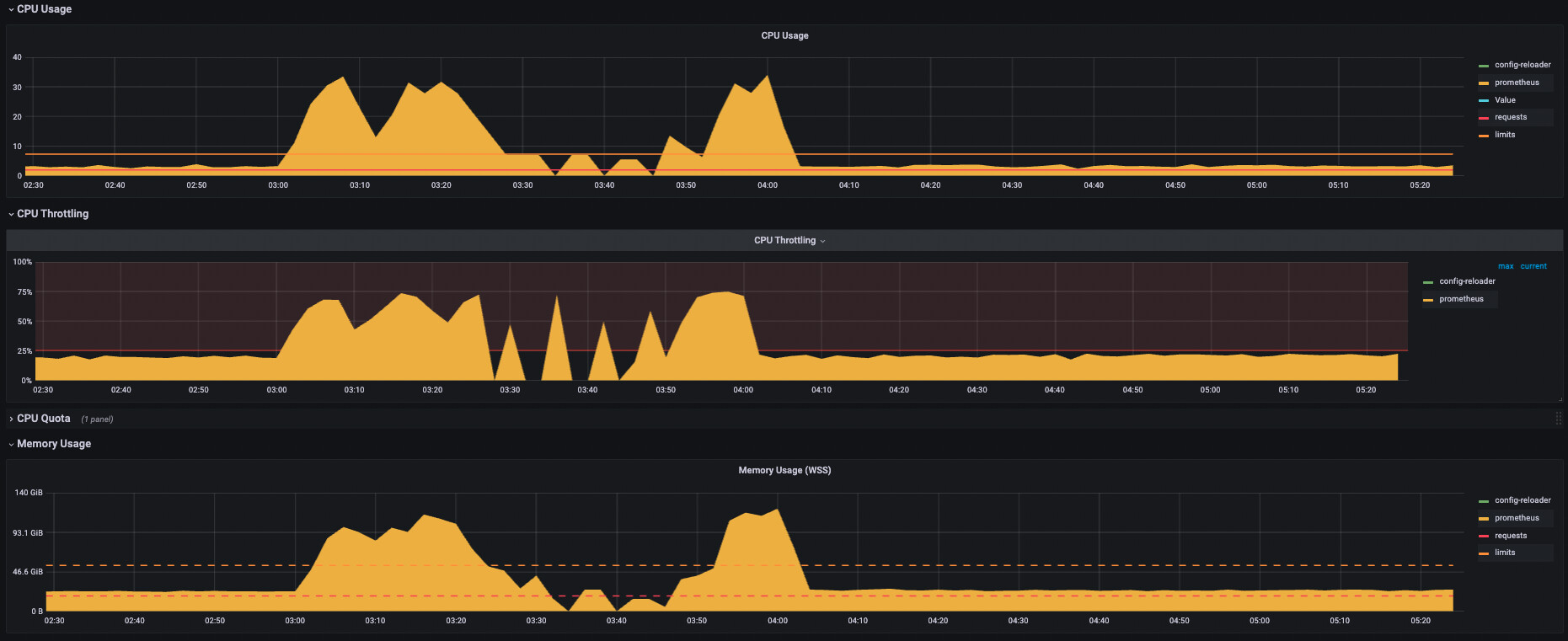
Cómo detectar y monitorizar el CPU throttling con Prometheus
Para que este enemigo deje de ser invisible, hace falta monitorizar métricas específicas de throttling, no solo el uso total de CPU. Con Prometheus y el stack habitual de observabilidad, puedes apoyarte en contadores como container_cpu_cfs_throttled_seconds_total, que acumula el tiempo total en segundos en el que un contenedor ha estado estrangulado.
Una consulta bastante útil en PromQL es sumar la tasa de aumento de este contador por pod en una ventana de tiempo reciente. Algo como la suma de la rate del throttling en los últimos 5 minutos por pod te permite ver quién está siendo frenado de forma activa, incluso aunque la CPU total del nodo parezca sobrada y no dé pistas claras.
También es interesante relacionar cuántos periodos totales de CFS ha tenido un contenedor con cuántos de esos periodos han sufrido throttling. Midiendo el cociente entre los periodos estrangulados y los periodos totales en una ventana (por ejemplo 5 minutos), puedes estimar el porcentaje de tiempo que una carga está queriendo trabajar y no puede por culpa del límite impuesto.
A partir de ahí, lo sensato es definir alertas que salten cuando se supera un umbral de throttling razonable para un pod o un namespace concreto. Así podrás actuar de forma proactiva: ajustar límites, separar cargas, revisar el diseño de la aplicación o decidir si te compensa dar más CPU a determinados servicios frente a otros.
Throttling térmico: cuando el hardware se protege bajando revoluciones
Más allá de los contenedores y Kubernetes, el throttling también aparece a nivel físico. Los procesadores de portátiles y smartphones modernos incluyen mecanismos de protección térmica que reducen su frecuencia de reloj al acercarse a ciertas temperaturas para evitar daños. Lo curioso es que, muchas veces, esta protección entra en juego antes de llegar al límite teórico (la Tjunction), de forma que el sistema parece saludable pero rinde mucho menos.
Algunos usuarios de portátiles, como quienes trabajan con modelos ThinkPad de generaciones pasadas, describen situaciones en las que, al alcanzar cierta temperatura de placa base —por ejemplo, alrededor de 80 °C en un sensor de la placa—, el equipo empieza a ir visiblemente más lento aunque las herramientas de monitorización no muestren un estado de throttling clásico. Los clocks parecen mantenerse, el sistema de gestión de energía no indica grandes cambios, pero la sensación de pesadez es evidente.
En estos casos puede intervenir no solo la CPU, sino también otros límites internos del fabricante, relacionados con la temperatura de la placa, la GPU integrada o incluso componentes de alimentación. El efecto final es similar: el equipo “levanta el pie del acelerador” de forma discreta para no sobrepasar un umbral térmico que podría comprometer la estabilidad o la vida útil del dispositivo.
En smartphones, este mismo fenómeno se conoce habitualmente como throttling térmico. El sistema operativo y el hardware trabajan coordinados para, ante un exceso de temperatura —provocado por juegos exigentes, apps pesadas o simplemente un ambiente muy caluroso—, bajar la frecuencia de CPU y GPU. El móvil se calienta, baja el rendimiento, los juegos van a tirones y las aplicaciones que antes eran fluidas empiezan a resentirse.

Cómo evitar que el móvil se arrastre por culpa del calor
En el día a día, la mejor defensa frente al throttling térmico en móviles es usar el sentido común. Acciones tan simples como no utilizar el teléfono mientras se está cargando pueden reducir muchísimo la temperatura. La carga ya de por sí calienta la batería y el circuito de alimentación, y si encima se le exige al procesador que dé el máximo, el margen térmico desaparece muy rápido.
También conviene evitar apoyar el móvil sobre superficies que retienen calor, como colchones, mantas o sofás, mientras se juega o se reproduce contenido pesado. Estas superficies dificultan la disipación y agravan el problema, sobre todo en sesiones largas de uso intensivo.
Otro frente importante es la gestión del software. Muchas aplicaciones se quedan en segundo plano consumiendo CPU y memoria RAM, acumulando carga de forma silenciosa. Cerrar con cierta regularidad las apps que no se usan libera recursos críticos que, de otro modo, mantienen al procesador trabajando de forma innecesaria, contribuyendo a que el terminal se caliente y entre en throttling antes de lo previsto.
Para quienes juegan, tiene todo el sentido del mundo ajustar la calidad gráfica. Reducir resolución, desactivar sombras y efectos especiales o elegir perfiles de rendimiento medio en lugar de alto disminuye la carga sobre CPU y GPU, facilita que se mantenga una tasa de frames más estable y reduce la probabilidad de que el teléfono se vea obligado a estrangular el rendimiento a mitad de partida.
Rate limiting y throttling en la capa de red y aplicaciones web
El concepto de throttling no se queda solo en la CPU o la temperatura: en el mundo web, se habla de rate limiting o throttling de peticiones HTTP para referirse a las políticas que limitan el número de solicitudes que un cliente puede hacer a un sitio web o API en un intervalo de tiempo dado. Este límite se suele aplicar por dirección IP, por cookie, por API key o por algún identificador de usuario.
El objetivo de estas políticas es doble. Por una parte, proteger la disponibilidad de la plataforma frente a abusos, automatismos o bots que lanzan demasiadas peticiones en poco tiempo, pudiendo saturar la infraestructura. Por otra, contribuir a la seguridad, mitigando ataques de fuerza bruta, credential guessing y otras tácticas donde un actor malicioso prueba credenciales o explota formularios a toda pastilla.
En la práctica, muchas CDN y WAF integran mecanismos de rate limit que permiten definir reglas del tipo “N peticiones por segundo y cliente” o “M peticiones POST por minuto y usuario”. Cuando se rebasa el umbral, las nuevas solicitudes se bloquean o se responden con un código HTTP 429 (Too Many Requests), o incluso con códigos personalizados en función de la política de la plataforma.
Un ejemplo clásico es el de redes sociales que, para aliviar la carga de su infraestructura, definen tasas máximas de uso para cada cuenta, independientemente de si el usuario accede desde la app oficial o desde clientes de terceros. Si un usuario utiliza varias aplicaciones conectadas a la misma cuenta, puede llegar al límite más deprisa que alguien que solo usa la aplicación principal, y desde su punto de vista podría interpretar ese freno como un problema de rendimiento cuando en realidad es una medida de control y protección.
Configuración avanzada de rate limiting en un WAF
En soluciones avanzadas de WAF y CDN, el rate limit se suele definir mediante comandos específicos en la configuración. Es habitual encontrarse con sintaxis donde se indica un nombre de la regla, el número máximo de peticiones, el periodo de tiempo, y parámetros opcionales como la duración del bloqueo o la activación de un CAPTCHA.
En un escenario típico podrías querer limitar a, por ejemplo, 20 peticiones por segundo y dirección IP. Una vez alcanzado ese valor, se bloquea al cliente durante 30 segundos y se le exige resolver un CAPTCHA para demostrar que no es un bot. El WAF se encarga de aplicar esta lógica, y el servidor de aplicación recibe muchas menos peticiones abusivas.
El resultado es que, a ojos del usuario o del desarrollador que no conoce la política, parece que el sitio “se ha vuelto caprichoso”: unas peticiones pasan, otras no, y en ocasiones todo responde más lento de lo normal. Pero lo que está ocurriendo de fondo es una regulación del flujo de tráfico para proteger la infraestructura: es un throttling de red deliberado, igual de importante para la estabilidad del sistema que los límites de CPU o el throttling térmico en hardware.
Este tipo de mecanismos también ayudan a contener costes en entornos cloud, evitando que comportamientos abusivos disparen el consumo de recursos. Durante auditorías y pruebas de penetración es frecuente encontrar APIs que, por carecer de rate limiting adecuado, podrían ser explotadas de forma masiva hasta el punto de provocar un consumo económico insostenible o dejar fuera de servicio a la organización.
Throttling en herramientas de auditoría de rendimiento: el caso de Lighthouse
Otra forma, a veces olvidada, de throttling invisible aparece cuando se usan herramientas de análisis como Lighthouse para evaluar el rendimiento de una web. Estas herramientas integran perfiles de simulación de red lenta y CPU limitada para reproducir escenarios realistas de usuarios con dispositivos modestos o conexiones pobres.
Si al lanzar Lighthouse no se ajustan bien los parámetros, es posible que se esté aplicando un throttling de red o de CPU emulada que no coincide con lo que se quiere medir. Por ejemplo, se puede forzar por defecto una simulación para móviles con conexión 3G lenta, mientras que el objetivo del análisis es el rendimiento en escritorio con buena conexión.
En esos casos, aunque la aplicación real no esté siendo estrangulada en producción, los informes de Lighthouse mostrarán tiempos de carga y métricas de experiencia de usuario mucho peores de lo que se observa en la práctica. Revisar opciones como el factor de forma emulado (móvil o escritorio) y la desactivación del throttling de red cuando no se necesita es esencial para interpretar correctamente los resultados y no confundir un entorno de prueba con la realidad.
Si los comandos de configuración de Lighthouse no responden como se espera, puede tratarse de incompatibilidades de versión, parámetros de línea de comandos mal escritos o perfiles por defecto que sobrescriben parte de la configuración. En cualquier caso, la idea de fondo se mantiene: el throttling es una herramienta útil para probar y proteger, pero si no se entiende bien puede llevar a diagnósticos equivocados sobre el rendimiento real de la aplicación.
Al final, todos estos escenarios —CPU limitada por CFS, protección térmica de hardware, rate limiting en WAF y throttling en herramientas de auditoría— apuntan a la misma idea: los sistemas modernos recurren constantemente a mecanismos de autocontrol que reducen el rendimiento de forma deliberada. Solo cuando se comprenden en detalle dejan de ser “invisibles” y se convierten en palancas que puedes ajustar a tu favor para encontrar un equilibrio sensato entre rendimiento, seguridad, estabilidad y coste.

Redactor especializado en temas de tecnología e internet con más de diez años de experiencia en diferentes medios digitales. He trabajado como editor y creador de contenidos para empresas de comercio electrónico, comunicación, marketing online y publicidad. También he escrito en webs de economía, finanzas y otros sectores. Mi trabajo es también mi pasión. Ahora, a través de mis artículos en Tecnobits, intento explorar todas las novedades y nuevas oportunidades que el mundo de la tecnología nos ofrece día a día para mejorar nuestras vidas.