- Maia 200 es el acelerador de inferencia de IA de segunda generación de Microsoft, fabricado en 3 nm y con más de 140.000 millones de transistores.
- El chip ofrece hasta 10 PFLOPS en FP4, 5 PFLOPS en FP8 y 216 GB de memoria HBM3e, priorizando eficiencia por euro/dólar frente a Trainium y TPU, y plantando cara a Nvidia.
- Está integrado en la infraestructura de Azure para dar servicio a Copilot, modelos de OpenAI y proyectos internos avanzados, con despliegue inicial en US Central y expansión progresiva.
- Forma parte de una estrategia "del silicio al servicio" para reducir costes estructurales, ganar independencia tecnológica y reforzar la posición de Microsoft en la guerra del silicio de la IA.

Microsoft ha dado un nuevo paso en su estrategia de infraestructura de inteligencia artificial con Maia 200, su acelerador de inferencia de segunda generación. El chip llega para apuntalar la oferta de Azure en plena explosión de la IA generativa y, de paso, para reducir la fuerte dependencia que la compañía mantiene de Nvidia y otros proveedores externos.
Lejos de ser un simple componente más, Maia 200 se presenta como la pieza central de un modelo integrado que va desde el silicio hasta los servicios en la nube. El objetivo es claro: ejecutar modelos de lenguaje de gran escala y sistemas de razonamiento avanzado con más rendimiento por euro invertido, controlando al máximo los costes operativos en los centros de datos.
Un acelerador pensado para la inferencia masiva

Maia 200 está diseñado específicamente para la fase de inferencia de modelos de inteligencia artificial, es decir, el momento en el que sistemas ya entrenados procesan consultas y generan respuestas en tiempo real. Es aquí donde se concentran millones de peticiones diarias de servicios como asistentes, chatbots corporativos o herramientas de productividad basadas en IA.
La compañía define a Maia 200 como el sistema de inferencia más eficiente que ha desplegado jamás en Azure. Según sus datos internos, el chip ofrece hasta un 30 % más de rendimiento por dólar (o por euro) que el hardware previo de su flota, un factor clave cuando el volumen de consultas crece de forma exponencial y la factura energética no deja de presionar a la baja los márgenes.
El nuevo acelerador sustituye en la práctica a Maia 100, la primera generación de este diseño, que nunca llegó a ponerse a disposición de los clientes. Con Maia 200, Microsoft pasa de un experimento de laboratorio a un despliegue real en sus centros de datos, alineando esta plataforma con servicios comerciales de gran visibilidad.
En este contexto, la apuesta por hardware propio encaja con la tendencia general de los grandes proveedores de nube, que buscan evitar depender en exclusiva de Nvidia y, al mismo tiempo, diferenciar su oferta frente a competidores como Google (TPU) o Amazon Web Services (Trainium e Inferentia), y ante problemas como retrasos en GPUs.
Arquitectura y proceso de fabricación: 3 nm y más de 140.000 millones de transistores

En el plano técnico, Maia 200 se construye sobre el proceso de 3 nanómetros de TSMC (nodo N3P), uno de los más avanzados que hoy se pueden fabricar en volumen. Cada chip integra del orden de 140.000 millones de transistores, un salto de complejidad que refleja la escala de los modelos de IA actuales y de las cargas de trabajo que se quieren soportar en los próximos años.
El diseño interno se articula alrededor de una jerarquía de cómputo en la que el elemento fundamental es el llamado “tile”, que actúa como una unidad autónoma con capacidad de cálculo y almacenamiento local. Cada tile incorpora dos motores principales: por un lado, la Tile Tensor Unit (TTU), enfocada a multiplicaciones de matrices y operaciones de convolución de alto rendimiento; por otro, el Tile Vector Processor (TVP), un motor SIMD muy programable para tareas que requieren mayor flexibilidad.
Varios tiles se agrupan en clusters con memoria SRAM compartida, lo que introduce un segundo nivel de localidad de datos. Esta organización permite coordinar de forma eficiente la ejecución entre múltiples tiles antes de escalar al nivel de sistema en chip completo, reduciendo cuellos de botella y mejorando el aprovechamiento del hardware.
El subsistema de memoria, una de las claves del rendimiento en IA, se ha diseñado para minimizar el tráfico fuera del chip y aliviar la presión de ancho de banda. La idea de fondo es sencilla, aunque no trivial de implementar: colocar la máxima cantidad posible de memoria rápida cerca del cómputo para que los modelos no tengan que “esperar” constantemente a que lleguen los datos.
Memoria, formatos de precisión y rendimiento en PFLOPS
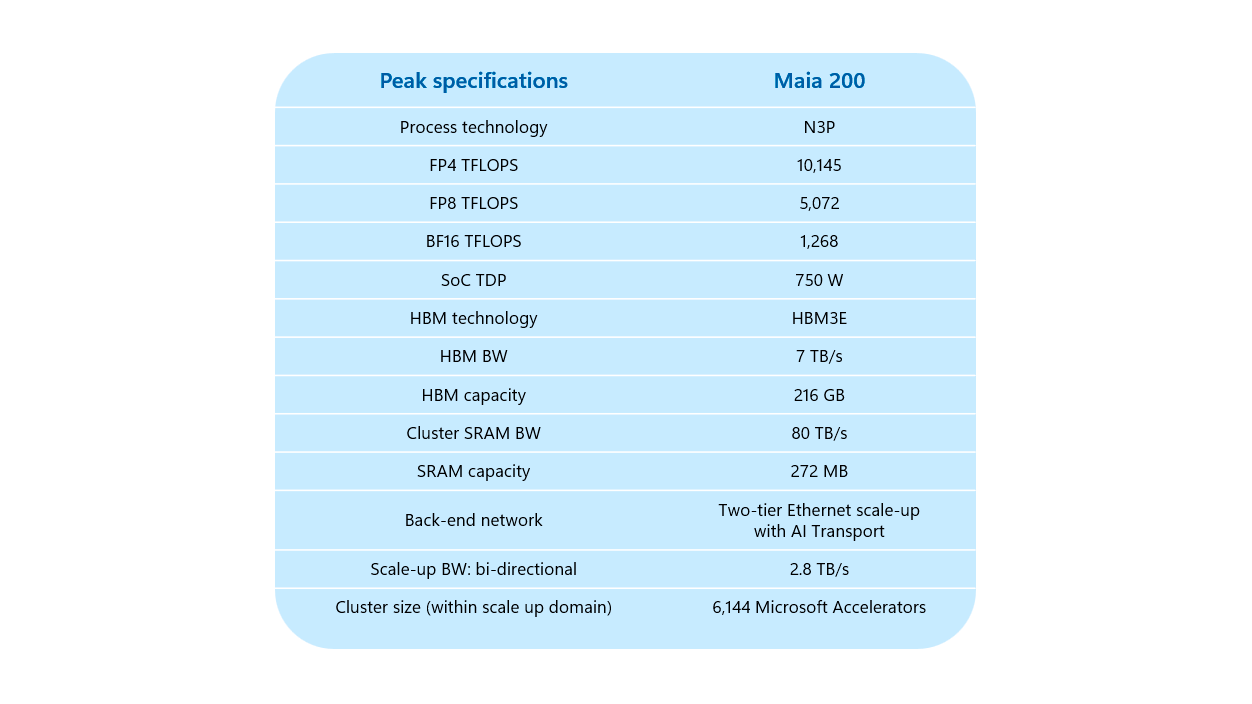
Una de las señas de identidad de Maia 200 es la combinación de memoria integrada y externa de muy alta velocidad. En el propio chip se incluyen 272 MB de SRAM, repartidos en distintos niveles (TSRAM en cada tile y CSRAM en cada cluster). Esta SRAM se gestiona por software, lo que permite un control detallado de la localidad de datos según la carga de trabajo.
A estos bloques se suman 216 GB de memoria HBM3e, un volumen cercano al cómputo que es especialmente relevante para modelos de lenguaje de gran escala y cuyo coste conviene vigilar junto al precio de la memoria GDDR6.
En cuanto a potencia de cálculo, Microsoft indica que el chip está optimizado para formatos de baja precisión como FP4 y FP8, que permiten exprimir mejor el rendimiento manteniendo una calidad de resultados adecuada para muchas aplicaciones de IA generativa y de razonamiento. Maia 200 alcanza alrededor de 10 PFLOPS en FP4 y 5 PFLOPS en FP8, además de situarse en torno a 1,3 PFLOPS en BF16.
El rendimiento en FP4, según las cifras de la compañía, sería ocho veces superior al de BF16 y aproximadamente el doble que el de FP8 a igualdad de condiciones. Esto se traduce en ganancias claras en tokens procesados por segundo, algo crítico en escenarios donde millones de usuarios generan texto, código o contenido multimedia de forma simultánea.
Con un TDP de unos 750 W por acelerador, Maia 200 se posiciona en la franja alta de consumo dentro de los chips para centros de datos, pero lo compensa con una relación rendimiento/energía que Microsoft presenta como una de sus principales bazas frente a las alternativas de la competencia.
Conectividad, escalabilidad y el protocolo AI Transport Layer
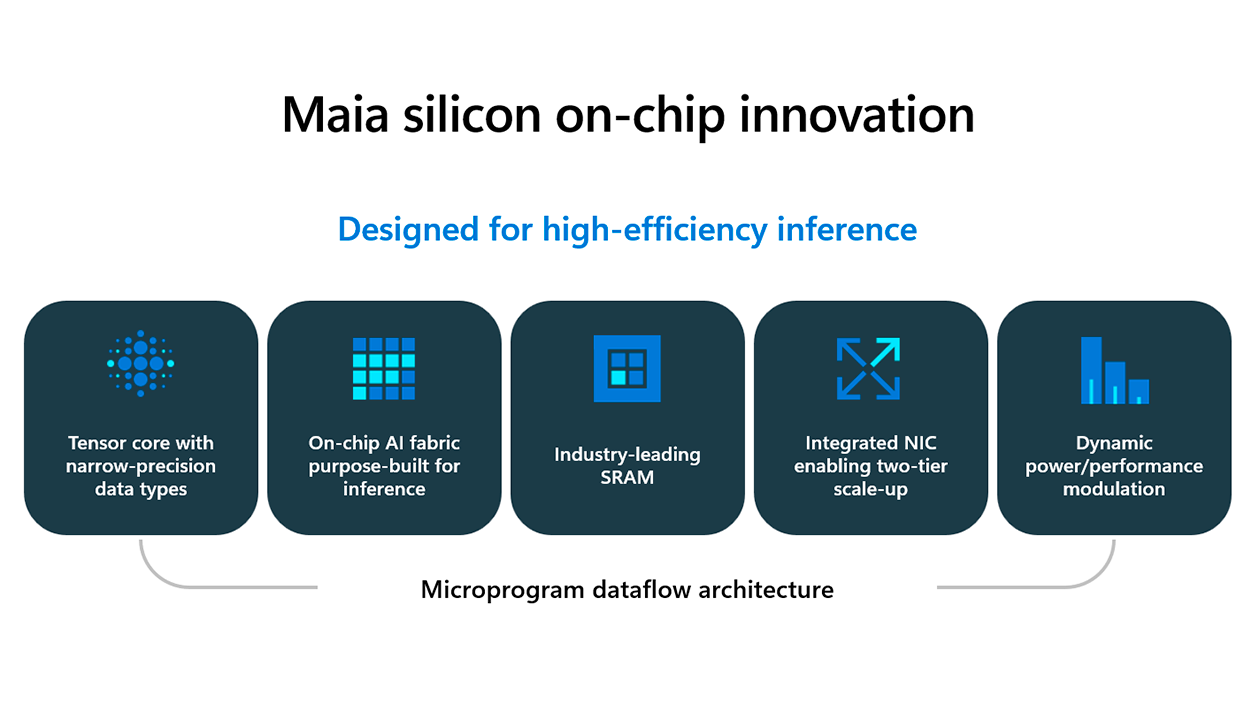
Además del cálculo puro, Maia 200 incorpora una capa de red avanzada que resulta esencial para escalar hasta miles de aceleradores trabajando en paralelo. El chip integra su propia tarjeta de red en el silicio, con un ancho de banda bidireccional de aproximadamente 2,8 TB/s, evitando así recurrir a tarjetas externas para la comunicación de alto rendimiento.
La comunicación entre nodos se articula a través de un protocolo específico denominado AI Transport Layer (ATL), que se ejecuta sobre infraestructura Ethernet estándar. ATL introduce técnicas como el packet spraying (reparto de paquetes por múltiples rutas) y el enrutamiento multipunto para mejorar la estabilidad y reducir la congestión en escenarios de tráfico intenso típico de la IA generativa.
Otro elemento relevante es el llamado Fully Connected Quad (FCQ), una topología que agrupa cuatro aceleradores Maia 200 mediante enlaces directos sin pasar por interruptores externos. Este enfoque reduce la latencia en las comunicaciones de tensores y simplifica la construcción de bloques modulares que luego se pueden replicar a gran escala.
Según Microsoft, esta arquitectura permite escalar hasta clústeres de 6.144 aceleradores Maia 200, una cifra alineada con las necesidades de entrenamiento e inferencia de los modelos de mayor tamaño, incluidas las futuras generaciones de modelos de lenguaje multimodales.
En la práctica, el chip se monta en bandejas o racks que alojan conjuntos de varios aceleradores, lo que facilita su integración en los centros de datos existentes. La compañía ha diseñado el sistema para que pueda funcionar tanto con refrigeración por aire como con soluciones líquidas más avanzadas, de forma que se adapte a distintas configuraciones de infraestructura.
Integración en Azure, Copilot y modelos de OpenAI
Maia 200 no llega solo, sino como parte de un enfoque que Microsoft define como “del silicio al servicio”. La idea es que hardware, software, redes y modelos se diseñen y optimicen en conjunto para maximizar el rendimiento y minimizar los costes de explotación.
Los primeros sistemas basados en Maia 200 ya se están desplegando en la región US Central de Azure. Estos clústeres iniciales alimentan modelos avanzados del equipo de Microsoft Superintelligence, iniciativas de Microsoft Foundry centradas en la creación y escalado de modelos personalizados, y sobre todo Microsoft Copilot, la familia de asistentes integrados en aplicaciones como Microsoft 365.
La compañía apunta directamente a ofrecer soporte para modelos de nueva generación, incluidos los GPT-5.2 de OpenAI, alineados con la alianza estratégica que ambas empresas mantienen desde los inicios de ChatGPT. La mejora en latencia y coste por consulta debería traducirse en respuestas más rápidas y sostenibles a gran escala para estos servicios.
Más allá de Estados Unidos, la previsión es ir extendiendo Maia 200 a otras regiones de Azure, incluidas las europeas, a medida que se validen el comportamiento, la eficiencia y la estabilidad del sistema en producción. Para empresas y administraciones que operan en la UE, será relevante ver en qué plazos aterrizan estos aceleradores en los centros de datos locales por cuestiones de soberanía de datos y cumplimiento normativo.
En paralelo, el chip se integra con un ecosistema de herramientas de desarrollo que busca no obligar a los programadores a cambiar de hábitos de la noche a la mañana, facilitando su adopción en proyectos existentes.
Herramientas para desarrolladores y ecosistema de software
Para que Maia 200 no se quede en un ejercicio de ingeniería interna, Microsoft acompaña el lanzamiento con un SDK específico orientado tanto a empresas como a universidades y proyectos de código abierto. El objetivo es crear una comunidad técnica que explore al máximo las capacidades del chip y contribuya a optimizar las cargas de trabajo.
El entorno de desarrollo mantiene compatibilidad con herramientas habituales como PyTorch, lo que permite portar modelos ya existentes con un esfuerzo razonable. También se ofrece soporte para el compilador Triton, pensado para aprovechar al detalle las particularidades del hardware sin renunciar a un lenguaje relativamente accesible para quienes ya trabajan con GPU y aceleradores.
Para los equipos que necesitan un control más fino, Microsoft pone a disposición el lenguaje Nested Parallel Language (NPL), diseñado para exprimir la jerarquía de tiles, clusters y memoria local del chip. Este enfoque, más cercano al metal, está orientado a optimizar al máximo la localidad de datos y la paralelización de rutinas críticas.
En la práctica, esta combinación de niveles de abstracción pretende que tanto grandes corporaciones como grupos de investigación académica puedan adaptar sus modelos al nuevo hardware sin partir desde cero. La compañía ha comunicado que algunos programas de acceso temprano ya se están dirigiendo a universidades y equipos de investigación con el fin de acelerar la adopción.
Con ello, Microsoft intenta que Maia 200 se perciba no solo como un acelerador propietario, sino como un bloque de construcción básico dentro de un ecosistema de software abierto y relativamente familiar para la comunidad de IA.
Impacto económico, estratégico y la guerra del silicio
En el plano económico, el desarrollo de Maia 200 se enmarca en una batalla más amplia por el control de la infraestructura que sustenta la IA generativa. Cada consulta que pasa por Copilot, por un modelo de OpenAI alojado en Azure o por una aplicación empresarial de IA conlleva un coste que depende en buena medida del hardware utilizado.
Al contar con su propio chip de inferencia, Microsoft busca reducir costes estructurales, aumentar la previsibilidad del gasto y ganar poder de negociación frente a proveedores externos. Si la promesa de un 30 % más de rendimiento por dólar se materializa de forma consistente en producción, la compañía podría mejorar de forma sensible sus márgenes en servicios de IA.
Esta estrategia también tiene una lectura geopolítica y de soberanía tecnológica. En un momento en el que Europa y otras regiones debaten sobre la autonomía digital y el control de los datos, disponer de hardware propio integrado en una nube global refuerza la posición de Microsoft como socio tecnológico de grandes empresas y administraciones públicas.
El lanzamiento de Maia 200 se suma a los movimientos de Google con sus TPU y de Amazon con Trainium e Inferentia, en lo que muchos analistas ya califican como una auténtica “guerra del silicio”. El liderazgo en esta batalla no solo se mide en PFLOPS, sino en la capacidad de ofrecer IA potente, eficiente y económicamente viable a largo plazo.
De momento, Nvidia sigue dominando el mercado de aceleradores de IA, pero la apuesta de los grandes proveedores de nube por sus propios chips apunta a un escenario de mayor diversificación y competencia, en el que cada actor intentará controlar la mayor parte posible de la cadena de valor, desde el diseño del silicio hasta las aplicaciones finales que usan los usuarios.
Con Maia 200, Microsoft no solo incorpora un nuevo acelerador a su catálogo, sino que refuerza una estrategia de fondo orientada a controlar la infraestructura de IA extremo a extremo y ajustar la economía de la inferencia. La combinación de un diseño en 3 nm, memoria HBM3e masiva, red integrada de alta capacidad y una estrecha integración con Azure, Copilot y los modelos de OpenAI sitúa a este chip como una pieza clave en la carrera por la IA generativa, en la que el coste por consulta y la eficiencia energética serán tan determinantes como la propia potencia bruta de cálculo.

Soy un apasionado de la tecnología que ha convertido sus intereses «frikis» en profesión. Llevo más de 10 años de mi vida utilizando tecnología de vanguardia y trasteando todo tipo de programas por pura curiosidad. Ahora me he especializado en tecnología de ordenador y videojuegos. Esto es por que desde hace más de 5 años que trabajo redactando para varias webs en materia de tecnología y videojuegos, creando artículos que buscan darte la información que necesitas con un lenguaje entendible por todos.
Si tienes cualquier pregunta, mis conocimientos van desde todo lo relacionado con el sistema operativo Windows así como Android para móviles. Y es que mi compromiso es contigo, siempre estoy dispuesto a dedicarte unos minutos y ayudarte a resolver cualquier duda que tengas en este mundo de internet.