- El algoritmo de Nagle reduce tinygrams limitando a un segmento pequeño sin ACK por conexión, mejorando la eficiencia en redes lentas pero añadiendo latencia.
- Su interacción con los ACK retrasados puede introducir pausas de hasta 500 ms en patrones write–write–read y protocolos de petición–respuesta.
- TCP_NODELAY y TCP_QUICKACK permiten desactivar Nagle y/o Delayed ACK para priorizar latencia en aplicaciones interactivas y sistemas distribuidos modernos.
- La decisión de usar o no Nagle debe basarse en el patrón de tráfico real: throughput masivo frente a latencia unidireccional crítica.
Cuando se trabaja con redes, sockets o simplemente te peleas con la latencia de aplicaciones TCP, es cuestión de tiempo que toparse con el famoso algoritmo de Nagle (Nagle’s Algorithm). Es uno de esos mecanismos del stack TCP/IP que casi nunca configuramos a mano al principio, pero que puede marcar la diferencia entre una app fluida y una que va “a tirones” con retardos misteriosos de cientos de milisegundos.
En este artículo vamos a desgranar con calma qué es el algoritmo de Nagle, qué problema pretendía resolver en los años 80, cómo se combina (a veces fatalmente) con el mecanismo de ACK retrasados (Delayed ACK), cuándo conviene desactivarlo con TCP_NODELAY y qué opciones tenemos en los principales sistemas operativos para tunear su comportamiento. Todo explicado de forma sencilla.
Qué es el algoritmo de Nagle y qué problema intenta resolver
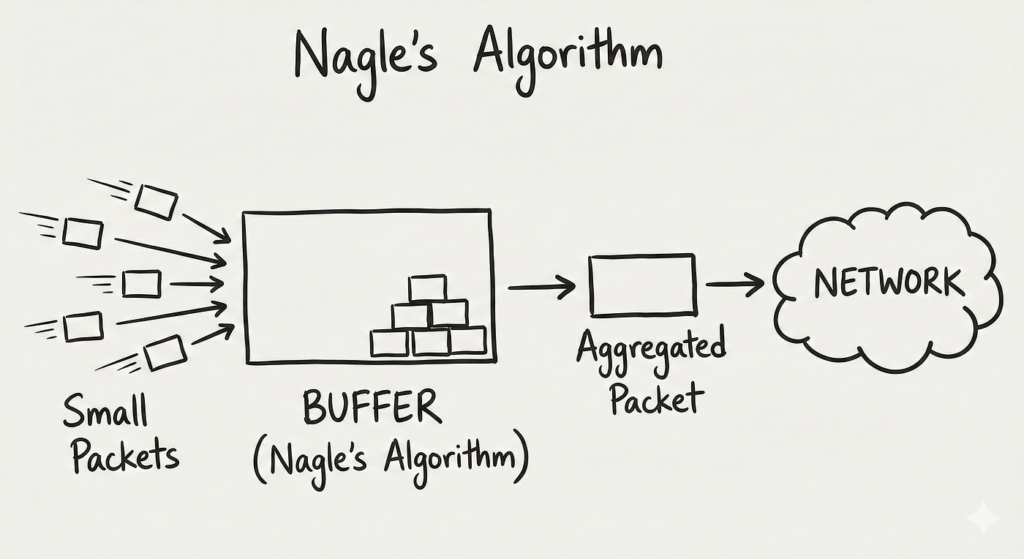
El algoritmo de Nagle nace de una necesidad muy concreta: evitar la avalancha de paquetes diminutos (tinygrams) que saturaban redes lentas en los primeros tiempos de TCP. Piensa en aplicaciones de terminal interactivas, donde cada pulsación de tecla mandaba un solo byte: por cada carácter viajaban 1 byte útil más 20 bytes de cabecera TCP y 20 de IP. Es decir, 41 bytes en total, de los que solo 1 era realmente de datos: un overhead de un 4000 %, una auténtica barbaridad si se repite miles de veces.
John Nagle propuso una solución “simple y elegante”: mientras haya datos enviados sin reconocer (sin ACK) en una conexión TCP, el emisor debe contenerse y no seguir enviando pequeños segmentos nuevos. De esta forma, en lugar de disparar paquetitos minúsculos uno tras otro, el sistema espera a que lleguen los ACK o a acumular más datos, de modo que se formen segmentos más grandes y eficientes.
En términos sencillos, la idea es que una conexión TCP solo puede tener un único segmento pequeño sin confirmar en vuelo. El resto de pequeños fragmentos generados por la aplicación se van quedando en el buffer del socket hasta que el segmento pequeño pendiente recibe su reconocimiento, momento en el que el sistema empaqueta lo acumulado en un segmento mayor y lo envía de golpe.
Esta lógica hace que el algoritmo sea en cierto modo autodaptativo: cuanto más lenta está la red o mayor es el retardo, más tardan en regresar los ACK y más se agrupan los datos en cada segmento. En enlaces WAN de alta latencia y ancho de banda relativamente limitado, esto era oro puro para mejorar la eficiencia global del tráfico.
Definición formal y funcionamiento interno
La especificación original del algoritmo de Nagle, recogida en la RFC 896 sobre control de congestión en redes IP/TCP, resume su comportamiento así: se debe inhibir el envío de nuevos segmentos TCP cuando llegan datos desde la aplicación si aún hay datos previamente transmitidos que no han sido reconocidos. A partir de esta definición, muchas implementaciones lo expresan en pseudocódigo.
En términos prácticos, la lógica para cada conexión TCP puede formularse de la siguiente manera: si llegan nuevos datos y la ventana de envío (la cantidad de datos no reconocidos permitidos) es mayor o igual al MSS, y además hay al menos MSS bytes en el buffer, se envía de inmediato un segmento de tamaño completo MSS. Si no se cumple esa condición, pero todavía quedan datos sin confirmar “en la tubería”, esos nuevos datos se encolan y se espera a recibir un ACK. Cuando no hay datos sin reconocer, cualquier nuevo dato recibido desde la aplicación se manda enseguida.
De fondo, lo que manda es la relación entre el MSS (Maximum Segment Size), el tamaño de ventana y el volumen de datos que la aplicación va escupiendo poco a poco. Si el flujo de la aplicación es muy granular (muchas escrituras pequeñas), Nagle hace de “embudo” y agrupa, si es más voluminoso el impacto se diluye y el algoritmo molesta menos.
Algunas descripciones más modernas añaden pequeños matices, como disparar el envío también cuando los datos acumulados alcanzan la mitad del tamaño de la ventana o superan el MSS, pero el corazón del mecanismo sigue siendo el mismo: no mandar el siguiente segmento pequeño hasta que el anterior se confirme.
Delayed ACK: reconocimientos retrasados para reducir overhead
En paralelo a Nagle, y casi en la misma época, se introdujo otra optimización en TCP que hoy es igual de famosa: los ACK retrasados (Delayed ACK). La idea era muy razonable para las redes de entonces: si acabas de recibir un segmento y estás a punto de enviar datos de vuelta, ¿por qué no esperar un poco y aprovechar ese paquete de salida para “enganchar” el ACK (piggybacking) en la misma cabecera?
Este mecanismo se basa en un temporizador: al recibir datos, el receptor se guarda el ACK y espera un pequeño intervalo (típicamente entre 200 y 500 ms) a ver si en ese tiempo aparece tráfico saliente al que pueda añadir el reconocimiento. Si no llega nada, cuando el temporizador expira se envía el ACK suelto.
El resultado es que se reduce el número total de ACK que circulan por la red, lo que ahorra cabeceras TCP/IP y disminuye la carga en routers y extremos. En muchos casos, sobre todo en protocolos interactivos con eco de caracteres (como ciertas configuraciones de Telnet), el receptor consigue agrupar varios ACK en uno solo sin penalizar percepción de la latencia.
Sin embargo, esta técnica tiene una cara B: ese retardo deliberado de hasta medio segundo puede ser letal para ciertas aplicaciones sensibles al tiempo. Y cuando se combina con el algoritmo de Nagle, los efectos indeseados se disparan, generando bloqueos y pausas periódicas muy difíciles de diagnosticar a primera vista.
La combinación explosiva: Nagle + Delayed ACK
El gran problema práctico de Nagle no aparece por sí solo, sino cuando se junta con los ACK retrasados. Ambas funcionalidades se diseñaron de forma independiente en los primeros 80 y, según el propio Nagle, la combinación “es terrible”. No hay coordinación explícita entre ellas, de modo que pueden caer en una especie de bucle de espera mutua.
Imagina una aplicación que hace dos escrituras seguidas sobre una conexión TCP y luego realiza una lectura, esperando los datos que genera el segundo write. Con Nagle activo, tras el primer pequeño segmento, el stack TCP no enviará el segundo paquete pequeño hasta que reciba el ACK del primero. Pero si el receptor aplica Delayed ACK, ese reconocimiento no saldrá inmediatamente, sino que esperará a poder adjuntarlo a un paquete de respuesta o a que salte el temporizador de 200-500 ms.
El resultado es un cuello de botella artificial: el emisor no manda el segundo segmento porque está esperando el ACK del primero, y el receptor no envía el ACK porque está esperando más tráfico. Ambos se quedan bloqueados hasta que el temporizador de ACK retrasado expira, introduciendo una latencia extra de hasta 500 ms en cada secuencia de este tipo.
Este patrón es especialmente dañino en protocolos de petición-respuesta no pipelinizados, como HTTP sobre conexiones persistentes cuando las peticiones o respuestas se dividen en varios segmentos y el último paquete es parcial. Con el algoritmo original, si una escritura generaba 2n segmentos donde los primeros 2n−1 eran de tamaño completo y el último era pequeño, TCP retenía ese último mientras esperaba un ACK. Si además el receptor retrasaba los ACK, el pequeño segmento se quedaba atrasado hasta medio segundo.

Cuándo tiene sentido desactivar Nagle: TCP_NODELAY
Los stacks TCP modernos suelen exponer una opción de socket para apagar Nagle de forma explícita: la conocida opción TCP_NODELAY. Está disponible desde 4.2BSD (1983) y se ha heredado en multitud de descendientes, incluyendo la mayoría de sistemas Unix, macOS y Windows. En AIX y Windows, por ejemplo, Nagle viene activado por defecto y se puede inhabilitar por socket con esta bandera.
Desactivar el algoritmo tiene todo el sentido del mundo cuando la prioridad absoluta es la latencia unidireccional baja y el volumen de datos por mensaje es pequeño, pero muy frecuente. En el ámbito del gaming, hay casos típicos son videojuegos multijugador en tiempo real, escritorios remotos donde cada movimiento de ratón debe notarse instantáneamente o herramientas interactivas que envían pulsaciones de teclas una a una, como telnet o rsh.
En estos entornos, ese retardo de cientos de milisegundos que puede introducir la dupla Nagle + Delayed ACK es inaceptable: el usuario percibe claramente que la interfaz “no responde” a tiempo. De ahí que muchas aplicaciones de baja latencia activen TCP_NODELAY en todas sus conexiones, sacrificando algo de eficiencia en cabeceras a cambio de una interacción mucho más ágil.
También es habitual que frameworks y librerías para protocolos “charlatanes” (chatty) como ciertos túneles SSL/TLS, soluciones tipo Citrix o sistemas que hacen muchos intercambios cortos de control opten por desactivar Nagle de serie, porque en la práctica les cuesta más en latencia que lo que ahorran en cabeceras.
En cambio, para tráfico masivo tipo descargas HTTP, SOAP, XMLRPC o transferencias de ficheros de gran tamaño, donde lo que domina es el throughput y el coste de cada cabecera es insignificante frente al volumen de datos, mantener Nagle activo no suele ser problemático y, en muchos casos, tampoco se nota diferencia al apagarlo.
¿Sigue teniendo sentido Nagle en sistemas modernos?
Si miramos las redes actuales, con datacenters donde una ida y vuelta (RTT) se mide en centenas de microsegundos o pocos milisegundos entre regiones cercanas, la justificación original de Nagle pierde fuerza. Bloquear el envío de un segmento hasta el siguiente ACK ya no supone segundos de espera, pero sí puede ser un obstáculo innecesario cuando cada microsegundo cuenta.
Además, hoy en día es raro que aplicaciones serias manden paquetes de 1 byte a pelo. La mayoría de sistemas distribuidos, bases de datos y servicios backend construyen mensajes más gordos, usan TLS (que ya añade su propia sobrecarga) y serializan datos con JSON, Protobuf y derivados. El problema de fondo de los tinygrams se ha “subido de nivel” y se gestiona en gran medida desde la capa de aplicación, que suele agrupar lógicamente la información antes de volcarla al socket.
Por eso muchos ingenieros que diseñan servicios de baja latencia en centros de datos modernos parten de una regla muy pragmática: para su tráfico de control interno, la opción segura es activar TCP_NODELAY siempre, y si hay problemas de throughput ya se tratarán de otra manera. En otras palabras, mejor arriesgarse a gastar unas cuantas cabeceras extra que introducir bloqueos de varias RTT en puntos críticos de la lógica de negocio.
Esto no significa que Nagle haya dejado de tener utilidad, sobre todo en contextos de enlaces estrechos o muy ruidosos (por ejemplo, SLIP, ciertos enlaces móviles o satélite) donde cada paquete es caro. Pero sí refuerza la idea de que su uso debe ser consciente: en muchos despliegues empresariales actuales, el valor por defecto de tenerlo activado no es el que mejor encaja con las aplicaciones que corren encima.
Un argumento adicional es que la propia recomendación de Nagle para evitar comportamientos patológicos pasa por que las aplicaciones no sigan el patrón write-write-read, sino write-read-write-read o bien write-write-write agrupando y vaciando el buffer solo cuando realmente toca. Esto reafirma que la responsabilidad de no “churretear” bytes al socket debería recaer, idealmente, en el código de usuario.
Desactivar Delayed ACK: TCP_QUICKACK y otros mecanismos
Otra vía para esquivar los problemas de la pareja Nagle + Delayed ACK es actuar en el otro lado: en lugar de apagar Nagle, desactivar o suavizar el comportamiento de los ACK retrasados. Aquí la situación es más desigual, porque las interfaces varían bastante entre sistemas operativos.
En Linux existe el flag TCP_QUICKACK desde el kernel 2.4.4 (2001), que permite pedir al stack que reconozca los segmentos entrantes de forma más rápida. También hay mecanismos similares o relacionados en Windows, como la operación SIO_TCP_SET_ACK_FREQUENCY, y parámetros de registro como TcpAckFrequency que, si se ponen a 1, fuerzan el envío más inmediato de los ACK.
En FreeBSD, el comportamiento por defecto de los ACK diferidos se controla mediante el parámetro sysctl net.inet.tcp.delayed_ack, que se puede ajustar para hacer los reconocimientos más agresivos o relajados según las necesidades. Sin embargo, en Linux no hay un conmutador global equivalente tan simple: la gestión del ACK retrasado está más embebida en la lógica interna de TCP.
Aunque estas opciones existen, muchos desarrolladores de sistemas distribuidos las usan con cautela. Por un lado, no son portables entre plataformas, lo que complica escribir código genérico mantenible; por otro, su semántica a veces es poco intuitiva y dependiente de la versión del kernel. Además, incluso con ACK rápidos, el kernel puede seguir reteniendo temporalmente datos que la aplicación preferiría mandar ya, por lo que no se elimina el problema de raíz.
Por todo esto, en muchos casos la táctica preferida es más directa: si la prioridad es que cada llamada a write( ) realmente signifique “envía esto ya”, se tiende a activar TCP_NODELAY y asumir el pequeño coste en cabeceras, en lugar de intentar domar el comportamiento de Delayed ACK con flags específicos del sistema.
Cómo decidir si activar o desactivar TCP_NODELAY
La gran pregunta práctica es: ¿cuándo conviene tener Nagle encendido, y cuándo es mejor desactivarlo con TCP_NODELAY? No hay una regla universal, pero sí algunas pautas bastante sólidas basadas en el tipo de tráfico y el comportamiento observado.
Si tu servicio maneja sobre todo transferencias voluminosas o no interactivas (descargas de ficheros, grandes respuestas HTTP, flujos de streaming bien bufferizados), la prioridad suele ser el throughput y la eficiencia general. En estos casos, dejar Nagle activado es razonable y rara vez introduce problemas perceptibles de latencia.
Por el contrario, si estás ante aplicaciones altamente interactivas que envían muchos mensajes pequeños: videojuegos online, escritorios remotos, Citrix, ciertos túneles SSL o protocolos que requieren numerosos “handshakes” cortos, Nagle tiende a ser un estorbo. Activar TCP_NODELAY suele traducirse en ganancias claras de reactividad para el usuario.
Una forma más analítica de verlo consiste en instrumentar la red y observar estadísticas como el número de tinygrams (paquetes con carga útil muy pequeña) y la cantidad de retrasos atribuibles a Nagle. Herramientas de análisis profundo de tráfico pueden ayudarte a ver qué porcentaje de tus paquetes son minúsculos y cuánto tiempo pasan “parados” por culpa de estos mecanismos.
Si, tras observar un tiempo, ves que hay muchos tinygrams pero pocos retrasos por Nagle, quizá sea buena idea mantenerlo activo porque está ayudando a reducirlos. Si, por el contrario, aparecen muchos tinygrams y un porcentaje alto de retrasos debidos al algoritmo, es una señal clara de que tu patrón de tráfico no está sacando partido a Nagle y desactivarlo puede ser beneficioso.
Como casi todo en rendimiento, la decisión final suele requerir varias iteraciones: tocar opciones, medir, esperar, revisar métricas y, en función de los resultados, ajustar de nuevo. Y todo ello con la vista puesta en que la mezcla de aplicaciones en una red cambia con el tiempo, así que lo que hoy funciona puede no ser ideal dentro de unos meses.
Alternativas y soluciones cuando TCP no encaja
En algunos escenarios extremos, ni siquiera desactivar Nagle y ajustar Delayed ACK basta para lograr la latencia deseada. Si tu aplicación envía tramas diminutas de forma constante y cualquier retraso adicional es inaceptable, puede que TCP no sea el mejor transporte para ti.
En estos casos, muchos desarrolladores optan por protocolos sin conexión como UDP, donde no hay control de congestión ni garantías de entrega, pero sí una latencia mínima y una total ausencia de mecanismos como Nagle o los ACK retrasados. Eso sí, hay que implementar en la capa de aplicación todo lo que TCP hace por ti: reenvíos, ordenación, control de pérdidas, etc.
Otra alternativa es rediseñar el propio protocolo de aplicación para evitar los patrones write-write-read problemáticos y reducir el número de intercambios mínimos necesarios para completar cada operación lógica. A veces, con un simple cambio en cómo se agrupan los mensajes, se consigue esquivar los peores efectos de Nagle sin tocar opciones de socket.
En entornos corporativos grandes también se recurre a ajustes en balanceadores de carga y proxies, donde se puede activar o desactivar TCP_NODELAY de forma dinámica según el tipo de tráfico detectado, o reducir los temporizadores de Delayed ACK de forma selectiva. Este enfoque permite adaptar el comportamiento a mezclas de tráfico muy heterogéneas sin tener que modificar todas las aplicaciones finales.
En cualquier caso, antes de tirar dinero en más hardware o enlaces nuevos, suele ser muy rentable revisar si los parámetros de TCP (Nagle, Delayed ACK, tamaño de ventana, buffers, etc.) están realmente alineados con el patrón de uso real de tu red. No es raro que ajustes bien hechos en estas capas logren mejoras notables sin cambiar ni un solo cable.
Visto todo lo anterior, entender a fondo cómo funciona el algoritmo de Nagle y cómo se pelea (o se lleva bien) con Delayed ACK, TCP_NODELAY y TCP_QUICKACK es casi obligatorio si te preocupa la latencia y el rendimiento en tus aplicaciones TCP: al final, decidir si conviene favorecer eficiencia o inmediatez en cada caso es lo que marca la diferencia entre una red que “va sola” y otra que siempre parece ir con el freno de mano echado.
Redactor especializado en temas de tecnología e internet con más de diez años de experiencia en diferentes medios digitales. He trabajado como editor y creador de contenidos para empresas de comercio electrónico, comunicación, marketing online y publicidad. También he escrito en webs de economía, finanzas y otros sectores. Mi trabajo es también mi pasión. Ahora, a través de mis artículos en Tecnobits, intento explorar todas las novedades y nuevas oportunidades que el mundo de la tecnología nos ofrece día a día para mejorar nuestras vidas.