- Nemotron 3 Super es un modelo abierto híbrido Mamba–Transformer–MoE con 120.000 millones de parámetros totales y 12.000 millones activos
- Su ventana de contexto de 1 millón de tokens y la técnica Latent MoE lo orientan a sistemas de agentes y tareas de largo recorrido
- Está optimizado para GPU NVIDIA Blackwell con formato NVFP4, logrando hasta 4 veces más velocidad que en Hopper a 8 bits
- La licencia Open Model de NVIDIA permite uso comercial y derivados, con algunas restricciones ligadas a seguridad y propiedad intelectual

La llegada de NVIDIA Nemotron 3 Super marca un movimiento claro hacia una nueva generación de modelos abiertos pensados, no tanto para simples chats, sino para sistemas de agentes autónomos que trabajan a gran escala. En lugar de centrarse solo en maximizar puntuaciones en benchmarks de razonamiento clásico, este modelo prioriza la eficiencia, la gestión de contexto enorme y el rendimiento en producción.
En un momento en el que proliferan las plataformas de IA que encadenan varios modelos para planificar, coordinar y ejecutar tareas de principio a fin, Nemotron 3 Super se posiciona como una base técnica diseñada desde el inicio para estos escenarios multi‑agente. Su combinación de arquitectura híbrida, contexto de un millón de tokens y licencia comercial abierta lo convierten en una opción que muchas empresas europeas van a mirar con atención cuando comparen alternativas frente a servicios cerrados.
Qué problema intenta resolver Nemotron 3 Super
Los sistemas multi‑agente que se usan para ingeniería de software, ciberseguridad o análisis documental masivo generan fácilmente hasta 10 o 15 veces más tokens que una conversación típica. Eso se traduce en latencias más altas, costes crecientes y dificultades serias para escalar cuando se trabaja con modelos densos tradicionales que activan todos sus parámetros en cada paso de inferencia.
Este cuello de botella es el que empuja a NVIDIA a presentar Nemotron 3 Super como parte de la familia Nemotron 3, junto a variantes como Nano y Ultra, enfocando el diseño específicamente a flujos de trabajo agénticos en entornos corporativos. El objetivo no es solo ser “otro LLM grande”, sino ofrecer una pieza de infraestructura que pueda sostener productos de IA complejos sin que los costes de operación se disparen.
Arquitectura híbrida: Mamba, Mixture of Experts y predicción multi‑token
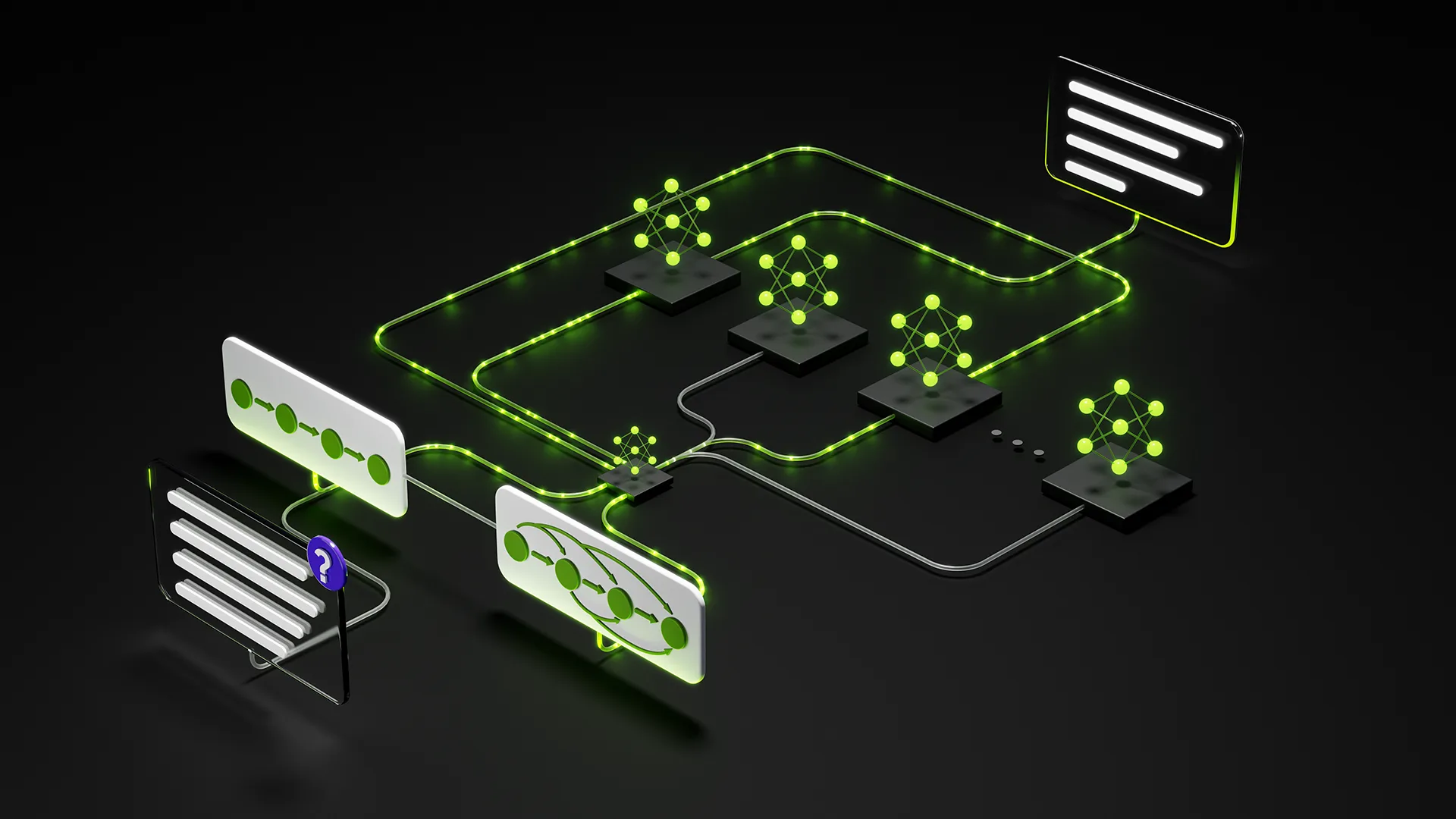
Lo más llamativo de Nemotron 3 Super no es únicamente su tamaño, sino la forma en que combina distintas ideas arquitectónicas en un esquema coherente. El modelo suma 120.000 millones de parámetros totales, pero solo 12.000 millones se activan por inferencia, gracias a un enfoque de mezcla de expertos y a una disposición de capas que rompe con el transformer denso clásico.
Backbone Mamba-Transformer con contexto extremo
El corazón del modelo alterna capas Mamba‑2, basadas en State Space Models, con capas de atención tipo Transformer situadas como “anclas globales”. Las capas Mamba procesan secuencias de forma lineal en el tiempo, lo que permite manejar cantidades enormes de texto con un coste mucho más contenido que la autoatención plena.
Las capas Transformer, por su parte, se utilizan donde hace falta razonamiento global o recuperación de información muy dispersa, como al navegar por una base de código o al cruzar informes financieros extensos. Esta combinación permite que el modelo trabaje con una ventana de contexto de hasta 1 millón de tokens sin que las cachés de claves y valores saturen la memoria de la GPU.
Latent Mixture‑of‑Experts: más especialistas al mismo coste
La parte MoE del modelo sigue un enfoque denominado LatentMoE. En lugar de enrutar cada token a expertos completos en la dimensión original, el sistema proyecta primero las representaciones a un espacio latente comprimido y, a partir de ahí, reparte la carga entre especialistas. Con esta estrategia se pueden consultar hasta cuatro veces más expertos por token manteniendo el mismo coste computacional.
En la práctica, esto significa que un solo modelo puede cambiar con fluidez entre lenguajes de programación, SQL, análisis de texto y diálogo dentro de una misma sesión de agente. Para productos que mezclan generación de código, razonamiento sobre datos y conversación natural, esta granularidad ayuda a evitar bloqueos o respuestas inconsistentes cuando la carga de trabajo se vuelve compleja.
Multi‑Token Prediction para acelerar la generación
Además de la estructura híbrida, Nemotron 3 Super incorpora Multi‑Token Prediction (MTP). Mientras que los LLM convencionales predicen un solo token en cada paso, este mecanismo permite anticipar varios tokens futuros al mismo tiempo, actuando como una especie de “borrador integrado” que habilita decodificación especulativa nativa.
En pruebas de generación estructurada, especialmente en código y llamadas a herramientas, esta técnica proporciona aceleraciones de hasta 3 veces en tiempo de pared respecto a decodificadores estándar. Para equipos europeos que sirven grandes volúmenes de tráfico en aplicaciones SaaS basadas en IA, esa reducción directa de latencia puede marcar la diferencia entre un servicio cómodo y otro que se percibe lento.
Eficiencia en hardware: la ventaja de Blackwell y NVFP4

NVIDIA ha diseñado Nemotron 3 Super pensando en su ecosistema de hardware. El modelo se ha preentrenado de forma nativa en NVFP4, un formato de precisión de 4 bits creado para exprimir al máximo la arquitectura Blackwell. Esta combinación, según la propia compañía, permite lograr una inferencia hasta 4 veces más rápida que modelos de 8 bits ejecutados en GPUs Hopper, sin pérdidas apreciables de calidad.
En cuanto al despliegue, Nemotron 3 Super puede ejecutarse en configuraciones como 1x B200, 1x GB200, 2x H100, 1x H200 o 4x A100, lo que ofrece cierto margen de maniobra para organizaciones europeas con infraestructuras dispares. Para laboratorios de investigación, proveedores cloud regionales o empresas que operan centros de datos propios, esta flexibilidad facilita adaptar el modelo al parque de GPU ya disponible.
Rendimiento en benchmarks: contexto largo frente a razonamiento general

En el terreno de las métricas, Nemotron 3 Super presenta un perfil bastante claro: no pretende ser el número uno absoluto en todos los benchmarks de razonamiento general, pero sí destacar en throughput y gestión de contexto largo dentro de su segmento de modelos abiertos de 100.000 millones de parámetros.
En el benchmark DeepResearch Bench, centrado en la capacidad de un modelo para conducir investigaciones profundas y multi‑paso sobre grandes colecciones de documentos, Nemotron 3 Super figura en el primer puesto de su categoría. En escenarios de alto volumen, los datos difundidos por NVIDIA señalan hasta 2,2 veces más rendimiento que GPT‑OSS‑120B y aproximadamente 7,5 veces más throughput que Qwen3.5‑122B, lo que refuerza su orientación a usos intensivos en tokens.
En cambio, en pruebas de conocimiento general como MMLU‑Pro, Qwen3.5‑122B conserva cierta ventaja, con una puntuación cercana a 86,7 frente a unos 83,7 puntos de Nemotron 3 Super. En el benchmark GPQA sin herramientas ocurre algo parecido, con Qwen por delante. Donde Nemotron 3 Super sí se distancia con claridad es en medidas específicas de contexto largo, como RULER a 1 millón de tokens, donde alcanza en torno a 91,75 puntos frente a algo más de 22 de GPT‑OSS‑120B.
En el ámbito de la programación, referencias como LiveCodeBench v5 sitúan a Nemotron 3 Super por encima de algunos rivales cercanos, con una puntuación superior a 81 frente a algo menos de 79 en el caso de Qwen para esa prueba concreta. En SWE‑Bench con el framework OpenHands, Qwen sigue liderando, aunque Nemotron 3 Super queda por delante de GPT‑OSS, reforzando la idea de que se trata de un modelo muy competitivo en código y agentes, pero no necesariamente el más puntero en cada métrica académica.
Licencia Open Model de NVIDIA: uso comercial con ciertas condiciones
Nemotron 3 Super se distribuye bajo la NVIDIA Open Model License Agreement, una licencia propia de la compañía, actualizada en otoño de 2025, que se desmarca de esquemas clásicos como MIT o Apache 2.0. El texto autoriza el uso comercial mundial, perpetuo y libre de royalties, de manera que empresas europeas pueden integrar el modelo en productos de pago sin necesidad de acuerdos individuales adicionales.
Otro punto clave de la licencia es que NVIDIA no reclama la titularidad de los resultados generados por el modelo. La responsabilidad legal y los derechos sobre los outputs recaen en el usuario o la organización que despliega el sistema, un aspecto especialmente relevante para compañías de la UE sujetas a normativas estrictas de protección de datos y propiedad intelectual.
La licencia permite, además, crear modelos derivados mediante fine‑tuning, siempre que se mantenga una atribución visible del tipo: “Licensed by NVIDIA Corporation under the NVIDIA Open Model License.” Esto facilita que startups, integradores y centros de investigación desarrollen variantes personalizadas adaptadas a dominios concretos —sanidad, industria, servicios financieros— sin renunciar a la apertura.
Las líneas rojas se centran principalmente en dos áreas: por un lado, la licencia se extingue si se desactivan o eluden las garantías de seguridad incorporadas sin implementar salvaguardas equivalentes; por otro, también finaliza si el usuario inicia litigios de propiedad intelectual contra NVIDIA alegando infracción relacionada con el modelo. Con ello, la compañía intenta proteger su ecosistema sin cerrar la puerta a un uso comercial amplio.
Adopción y ecosistema: de la comunidad técnica a la empresa

El anuncio de Nemotron 3 Super tuvo una respuesta rápida en la comunidad de desarrolladores. Miembros del equipo de producto de la propia compañía, como Chris Alexiuk, destacaron en redes que no solo se habían publicado los pesos del modelo, sino también un conjunto masivo de datos de entrenamiento, del orden de los 10 billones de tokens, junto con las recetas de entrenamiento completas. Para la comunidad europea de investigación en IA, este nivel de detalle ofrece material de estudio poco habitual en modelos de esta escala.
En el frente empresarial, Nemotron 3 Super se ha integrado como microservicio NIM dentro del ecosistema de NVIDIA, facilitando su despliegue tanto en la nube como en instalaciones locales. Fabricantes de infraestructura como Dell (AI Factory) y HPE ofrecen soporte para ejecutar el modelo on‑premises, mientras que proveedores de nube como Google Cloud y Oracle ya lo incluyen en su catálogo, con integración anunciada en AWS y Azure, dos de las plataformas cloud más utilizadas por empresas europeas.
Algunas compañías tecnológicas enfocadas en desarrollo de software, como CodeRabbit o Greptile, están adoptando Nemotron 3 Super para analizar bases de código de gran tamaño y asistir en tareas de programación. En el sector industrial, actores como Siemens están experimentando con el modelo para automatizar flujos de trabajo complejos en manufactura, mientras que firmas de ciberseguridad y análisis de datos como Palantir lo usan para reforzar sistemas de vigilancia, correlación de eventos y respuesta ante incidentes.
Desde la dirección de software de IA de NVIDIA, perfiles como Kari Briski han subrayado que, a medida que las organizaciones avanzan más allá de los chatbots básicos, se encuentran con una auténtica explosión del contexto necesario para sostener aplicaciones multi‑agente. Nemotron 3 Super se presenta como una respuesta técnica directa a ese reto.
Aplicaciones y oportunidades para Europa y España

Para startups y equipos técnicos en España y el resto de Europa, Nemotron 3 Super ofrece varias vías de aprovechamiento. La primera es la reducción del coste por token en pipelines multi‑agente, algo especialmente relevante para empresas SaaS que facturan en euros y deben controlar márgenes en un entorno de costes de energía e infraestructura elevados.
La segunda tiene que ver con el apoyo a tareas que requieren contexto largo, como el análisis de documentación jurídica, informes regulatorios, expedientes médicos anonimizados o bases de conocimiento técnicas. La ventana de 1 millón de tokens permite mantener en la memoria del modelo volúmenes de información que antes exigían arquitecturas adicionales de recuperación o segmentaciones muy agresivas.
Un tercer ámbito de interés está en el desarrollo de agentes especializados que combinen generación de código, orquestación de herramientas y diálogo. Para integradores españoles y europeos que construyen soluciones a medida para banca, seguros, industria o administración pública, poder desplegar un modelo de este tipo en su propia infraestructura —respetando la ubicación de los datos y la normativa local— supone una ventaja frente a depender exclusivamente de APIs cerradas alojadas fuera del Espacio Económico Europeo.
Por último, la disponibilidad de los pesos en plataformas como Hugging Face, OpenRouter o servicios gestionados compatibles abre la puerta a que universidades, grupos de investigación y comunidades de open source en Europa experimenten con el modelo, midan su comportamiento con datos locales y ajusten su rendimiento a lenguas como el español, el francés o el alemán mediante afinados específicos.
Nemotron 3 Super se sitúa así como un modelo abierto orientado a agentes, con fuerte énfasis en eficiencia, contexto largo y despliegue empresarial. No pretende ser el líder absoluto en todos los benchmarks generales, pero sí una pieza sólida para quienes necesitan construir sistemas complejos y escalables, conservando margen de maniobra sobre costes, datos y personalización en entornos como el mercado español y europeo.

Soy un apasionado de la tecnología que ha convertido sus intereses «frikis» en profesión. Llevo más de 10 años de mi vida utilizando tecnología de vanguardia y trasteando todo tipo de programas por pura curiosidad. Ahora me he especializado en tecnología de ordenador y videojuegos. Esto es por que desde hace más de 5 años que trabajo redactando para varias webs en materia de tecnología y videojuegos, creando artículos que buscan darte la información que necesitas con un lenguaje entendible por todos.
Si tienes cualquier pregunta, mis conocimientos van desde todo lo relacionado con el sistema operativo Windows así como Android para móviles. Y es que mi compromiso es contigo, siempre estoy dispuesto a dedicarte unos minutos y ayudarte a resolver cualquier duda que tengas en este mundo de internet.