- Las voces sintéticas delatan patrones anómalos en prosodia, timbre, pausas y emoción.
- Los detectores automáticos y marcas de agua ayudan, pero no son pruebas definitivas.
- La combinación de contexto, protocolos de verificación y biometría de voz aumenta la seguridad.
- La voz es un dato biométrico protegido y su uso está regulado por RGPD y la Ley de IA de la UE.

Vivimos en un momento en el que cualquier persona puede clonar una voz con apenas unos segundos de audio. Desde llamadas de estafa que imitan a un familiar hasta audios virales de políticos o famosos, distinguir si una voz es auténtica o está generada por IA se ha convertido en una habilidad básica de supervivencia digital.
Aunque los modelos de síntesis de voz mejoran a una velocidad brutal, todavía hay señales acústicas, visuales y contextuales que delatan a un deepfake de audio. Además, empiezan a aparecer herramientas de detección, marcas de agua digitales y protocolos específicos para empresas y administraciones que quieren blindarse frente a este tipo de engaños.
Qué es un deepfake de voz y cómo se genera
Un deepfake de voz es, en esencia, un modelo de IA entrenado para sonar como una persona concreta. A partir de grabaciones reales de ese hablante, la máquina aprende sus patrones de tono, timbre, acento, velocidad y cadencia, y luego es capaz de leer cualquier texto como si fuera esa misma persona.
Para conseguirlo se usan sistemas de texto a voz (TTS) impulsados por redes neuronales profundas. Durante años se trabajó con enfoques concatenativos (pegar trocitos de audio pregrabado) o paramétricos (modelos estadísticos del habla). Hoy lo habitual es usar arquitecturas basadas en deep learning, como WaveNet o Tacotron, que generan el sonido prácticamente desde cero.
En la práctica, basta con unos pocos minutos de voz clara y de buena calidad para entrenar un clon bastante convincente. Modelos punteros como VALL-E, de Microsoft, han llegado a demostrar imitaciones razonables con apenas tres segundos de muestra, lo que reduce al mínimo la barrera de entrada para los atacantes.
El flujo típico para crear un deepfake de voz suele seguir estos pasos: se toma una grabación real, se trocea en fragmentos muy pequeños, se alimenta una red neuronal con esas muestras para que aprenda las características de la voz y, cuando el modelo ya está entrenado, se le da un nuevo texto para que genere un archivo de audio sintético que imita al hablante original.
Estas tecnologías no solo copian el habla; muchas son capaces de recrear respiración, microsonidos de boca y matices expresivos básicos, lo que hace que el resultado suene cada vez menos robótico y más difícil de detectar solo con el oído.
Cinco señales para distinguir una voz real de una voz de IA en tiempo real
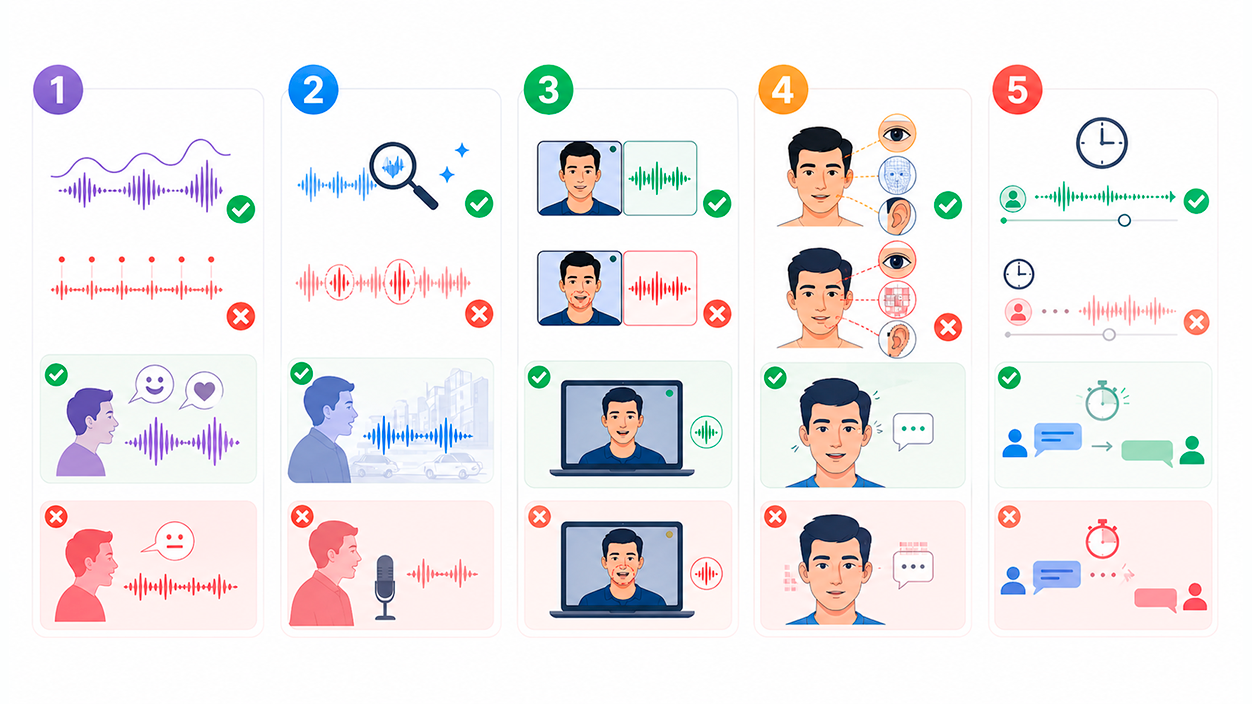
Cuando recibes una llamada extraña, una nota de voz sospechosa o estás en una videollamada que no te termina de cuadrar, conviene fijarse en una serie de pistas. No son infalibles, pero juntas ayudan bastante a intuir si estás escuchando a una persona real o a un modelo sintético.
Prosodia y entonación que “no cuadran”
La voz humana rara vez es completamente plana. Cambiamos el tono según la emoción, alargamos unas sílabas, acortamos otras, nos interrumpimos. En muchos audios generados por IA aparece una melodía de voz demasiado monótona o con saltos abruptos que no encajan con el contexto. Las pausas también son una pista: si son muy regulares, o caen en lugares extraños de la frase, huele a síntesis.
En una mala conexión de red puedes notar cortes o silencios, pero en cuanto vuelve la señal, la entonación base suena humana y emocional. Con IA, en cambio, se percibe una cadencia más mecánica, como si el discurso estuviera demasiado “bien montado”.
Artefactos de sonido: brillo metálico y colas raras
Otra alerta clara son los artefactos espectrales. Algunas voces sintéticas presentan un timbre ligeramente metálico en ciertas palabras, sibilancias (esos “s” y “sh” demasiado brillantes) o colas de sonido que se apagan de forma poco natural. A veces el audio suena “demasiado limpio” para el entorno en el que supuestamente se ha grabado.
En una grabación real es normal que el ruido de fondo y la calidad fluctúen: cambia la distancia al micrófono, se mueve la persona, entra un sonido de la calle. En muchos audios de IA esos defectos son sorprendentemente constantes o inexistentes.
Desajustes labios-voz en videollamadas
Si además de la voz tienes imagen, hay que mirar con lupa la sincronía entre labios y sonido. Los deepfakes de vídeo y las videollamadas manipuladas pueden mostrar un ligero retraso constante, o microanomalías como labios que “flotan” extrañamente sobre los dientes o movimientos bucales que no encajan con lo que se oye.
Con mala red también se pierde sincronía, pero el movimiento facial real sigue siendo orgánico, con microgestos creíbles. En modelos sintéticos, los pequeños desajustes se repiten de forma sistemática o tienen una calidad plástica que delata un renderizado.
Microgestos y detalles visuales extraños
Más allá de la boca, hay otros signos visuales: parpadeo muy escaso o a intervalos regulares, mirada fija, sombras que no cambian al ritmo de la cabeza, iluminación demasiado uniforme y cabello u orejas con píxeles raros. Son típicos de vídeos generados o retocados por IA.
En un problema de conexión normal, lo que sueles ver es un macropixelado burdo, congelaciones completas de imagen o saltos bruscos, no esos pequeños defectos de textura o bordes extraños en zonas muy concretas de la cara.
Latencia que no parece de red
La última pista es el tiempo que tarda la otra parte en contestar. Muchos sistemas sintéticos funcionan en bloques: reciben tu frase, la procesan y luego generan una respuesta completa. Eso puede producir pausas sospechosamente regulares antes de cada contestación, aunque la conexión sea buena.
En cambios, las malas conexiones generan latencias muy irregulares, avisos de “conexión inestable” y cortes imprevisibles. Si el retardo es siempre parecido, o de repente pasa de casi cero a varios segundos sin explicación técnica aparente, merece la pena desconfiar.
Señales en el propio audio: pausas, emoción y timbre
Incluso sin ver la cara de quien habla, el análisis atento del audio puede darnos mucha información. Aquí entra en juego tanto el oído como la observación sistemática de patrones de habla.
Las voces humanas tienen un conjunto de rasgos personales (tono, timbre, ritmo, acento) que varían mucho con el contexto: no hablamos igual en una reunión que en el bar con amigos. Las voces sintéticas, en cambio, tienden a mantener esos rasgos demasiado constantes, lo que se traduce en una sensación de monotonía o falta de vida.
Un truco útil es transcribir el audio, aunque sea de manera aproximada. Al verlo escrito se notan más fácilmente frases demasiado perfectas, ausencia total de muletillas, correcciones o vacilaciones. En un mensaje informal de voz es raro que alguien hable como si leyera un comunicado pulido al milímetro.
Herramientas de detección y marcas de agua: en qué ayudan y en qué no

Además del oído y el contexto, empiezan a proliferar detectores automáticos de voz sintética y sistemas de marcado en origen. Son muy útiles, pero conviene tener claro sus límites para no confiar ciegamente en ellos.
Los enfoques de detección actuales se dividen, a grandes rasgos, en dos familias: modelos de clasificación forense (que analizan el audio buscando patrones de IA) y marcas de agua digitales que se insertan en el contenido generado para permitir su identificación posterior.
Modelos de detección forense
Estos sistemas trabajan con grandes conjuntos de datos de voces reales y sintéticas. Analizan características acústicas como artefactos espectrales, prosodia anómala o patrones de ruido de fondo y aprenden a distinguir entre ambas categorías. Iniciativas como los retos ASVspoof proporcionan bases de referencia (escenarios de acceso lógico, físico y deepfake) para entrenar y comparar estos detectores.
En redacciones y medios ya se usan herramientas específicas, por ejemplo soluciones tipo VerificAudio o plataformas comerciales de biometría de voz, que combinan una capa de análisis sintético con verificación contextual (quién habla, desde dónde, en qué circunstancias). Su precisión real suele ser confidencial y, en audios muy comprimidos o llenos de ruido, aumenta el riesgo de falsos positivos.
Muchas plataformas que generan audio con IA ofrecen también su propio clasificador interno. Es el caso de servicios que detectan si un clip ha sido creado con su modelo concreto. Son bastante fiables sobre su propio contenido, pero no generalizan bien a voces sintetizadas con otros motores (por ejemplo, si el audio viene de Google, Meta u otra empresa distinta).
Marcas de agua en contenido generado
El otro gran enfoque es añadir, desde el origen, una señal imperceptible que identifique que el audio ha salido de un modelo de IA. Propuestas como AudioSeal de Meta insertan una marca capaz de indicar incluso qué fragmentos concretos han sido alterados, mientras que SynthID de Google plantea un etiquetado multimodal que se extiende de la imagen al audio y al texto.
El problema es que estas marcas no son indestructibles: compresión agresiva (como MP3), cambios de tono, eco artificial o manipulaciones maliciosas pueden debilitar la señal y disparar los falsos negativos. Además, solo sirven si el generador decide integrarlas; si un atacante usa un modelo sin watermark, ese audio será indetectable por esta vía.
En cualquier caso, los especialistas coinciden: la salida de un detector —ya sea una probabilidad de “x% IA” o una marca de agua encontrada— no debe usarse nunca como prueba definitiva. Es una pista inicial que se tiene que complementar con revisión humana, contexto y, en su caso, peritaje forense.
Biometría de voz y retos como ASVspoof: la batalla técnica
En el terreno más especializado, la comunidad científica y la industria trabajan con retos y bases de datos diseñados para poner a prueba los sistemas de verificación de locutores. Un ejemplo clave es el challenge ASVspoof, que se centra precisamente en ataques de suplantación de voz.
En la edición de 2021 se plantearon tres tareas: acceso lógico (audio inyectado digitalmente, con efectos de compresión y transmisión), acceso físico (ataques de repetición en entornos reales) y discurso deepfake (detección de conversiones de voz y TTS a partir de audio comprimido). El objetivo era medir hasta qué punto las soluciones actuales resisten escenarios realistas, con teléfonos, codecs y salas físicas de por medio.
Los resultados mostraron que, al aplicar técnicas avanzadas de deep learning a la detección, la robustez mejora de forma notable. También se comprobó que los intervalos no verbales del audio (silencios, respiraciones, ruidos de fondo) tienen un peso importante a la hora de desenmascarar voces falsas, especialmente en escenarios de acceso lógico y deepfake.
Empresas especializadas en biometría de voz utilizan estos datos para afinar sus modelos. Muchas combinan varias arquitecturas (redes convolucionales, modelos profundos, clasificadores en cascada) para que la decisión final de si una voz es real o falsificada no dependa de un único algoritmo. Así se reduce la probabilidad de error y se cubre mejor la diversidad de ataques posibles.
La biometría vocal, usada correctamente, permite no solo verificar identidades, sino también detectar artefactos propios de deepfakes mediante análisis espectral detallado, algoritmos de detección de patrones imposibles en la voz humana y comparaciones contra plantillas previamente registradas.
Métodos prácticos para usuarios: del oído al análisis de contexto
Más allá de la investigación y de las grandes plataformas, cualquier persona puede aplicar una serie de hábitos sencillos para no tragarse un audio falso. La clave es combinar tres capas: fuente, contenido y forma.
Lo primero es preguntarse: ¿de dónde sale ese audio? Si solo circula por redes sociales, grupos de mensajería o foros sin una fuente clara, hay motivos para sospechar. Conviene buscar el texto clave del mensaje en buscadores y comprobar si medios fiables, organismos oficiales o la persona supuestamente implicada han dicho algo sobre ello.
También es recomendable mirar si el audio ha sido ya desmentido por organizaciones de verificación de hechos o por plataformas especializadas en fact-checking. Muchas veces, los audios forman parte de una narrativa desinformadora más amplia, junto con otros contenidos similares ya desmontados.
A continuación hay que analizar el contenido: ¿el mensaje apela a la urgencia, al miedo o a la presión para que actúes rápido? ¿te pide datos sensibles, transferencias de dinero o acciones fuera de lo habitual? Este tipo de tácticas son típicas de las estafas, lleven o no IA detrás.
Por último, toca fijarse en la forma de la voz: monotonía, falta de emoción, pausas raras, pronunciaciones extrañas o timbre demasiado pulido. Si, además, el ruido de fondo no encaja con lo que se supone que estás oyendo (una “llamada desde la calle” con un silencio perfecto), la sospecha sube varios puntos.
Cómo usan esta tecnología las estafas y la desinformación

La clonación de voz se ha convertido en una herramienta muy tentadora para delincuentes y campañas de desinformación. No hace falta ser un experto: con aplicaciones en línea y un par de minutos de audio robado, se pueden montar llamadas o mensajes extremadamente creíbles.
Uno de los escenarios más preocupantes es el de las llamadas de suplantación de familiares o directivos. Si alguien conoce tu relación con otra persona y consigue grabar su voz —por ejemplo, a través de redes sociales, entrevistas o simples mensajes de audio— puede generar un deepfake que suene lo bastante real como para pedirte dinero, claves o decisiones urgentes.
También se han visto casos de audios virales de políticos, famosos o figuras públicas en los que supuestamente insultan, declaran algo escandaloso o anuncian medidas impactantes. Aunque algunos creadores marcan explícitamente que son montajes hechos con IA (por ejemplo, fans que recrean canciones imposibles de sus artistas favoritos), en otros casos se distribuyen sin contexto, con intención clara de manipular.
La mejora continua de las herramientas hace que ya no hablemos solo de voces que “se parecen un poco”. Hoy es posible generar grabaciones con emociones imitadas, cambios de ritmo creíbles y calidad casi de estudio, lo que complica todavía más la detección solo a oído.
Por eso, muchos expertos insisten en la importancia de la formación en ciberseguridad y en pensamiento crítico: reducir la cantidad de información personal y profesional que exponemos en redes, no compartir en abierto audios largos y limpios sin necesidad y, sobre todo, desarrollar reflejos para no actuar impulsivamente ante mensajes o llamadas sospechosas.
Buenas prácticas para proteger tu voz y no caer en el engaño
La mejor defensa combina escepticismo, medidas técnicas básicas y una gestión sensata de tu huella vocal. No se trata de vivir paranoico, sino de hacerle la vida más difícil a quien quiera suplantarte.
Cuida el consentimiento y la privacidad de tus audios
Evita compartir grabaciones de voz largas y de alta calidad sin un propósito claro. En entornos profesionales, es razonable exigir consentimiento explícito para grabar y analizar la biometría vocal, sobre todo si se van a usar para autenticación.
Si utilizas asistentes de voz en casa o en la oficina, conviene revisar la configuración y desactivar, en la medida de lo posible, el almacenamiento continuo de audio y la opción de “mejorar el servicio con mis grabaciones”. Cuantos menos datos se acumulen, menos material potencial habrá para entrenar un clon.
Limita y “ensucia” tu huella vocal pública
Si por trabajo o afición tienes que publicar vídeos, podcasts o entrevistas, puedes reducir el riesgo técnico bajando el bitrate de los archivos o añadiendo música de fondo. No es una barrera absoluta, pero complica el entrenamiento directo de modelos a partir de esas muestras.
En comunicaciones cotidianas, plantéate si necesitas mandar siempre notas de voz nítidas y largas. A veces un texto o una llamada breve son suficientes, y reduces la cantidad de material perfecto para clonar tu voz dando vueltas por apps y servidores.
Usa autenticación multifactor y “frases anti-deepfake”
Si en tu empresa o familia se suelen dar instrucciones sensibles por teléfono (transferencias, cambios de contraseñas, autorizaciones), es muy recomendable implantar un código de seguridad o frase dinámica. No tiene por qué ser algo súper complejo: puede ser una palabra clave que cambie periódicamente o preguntas contextuales del tipo “¿Cuál es la palabra del martes?” que solo los implicados conozcan.
Lo importante es que esa verificación sea revisada por una persona o por un sistema secundario independiente de la propia voz. Así, aunque alguien clonara la entonación, necesitaría además conocer la clave fresca de ese momento para completar el engaño.
Tecnologías de anulación y ruido blanco
Existen dispositivos y programas diseñados para interferir con los micrófonos cercanos mediante ultrasonidos o ruido de banda ancha. Pueden ser útiles en contextos muy sensibles para evitar grabaciones no autorizadas, pero tienen limitaciones claras: suelen ser caros, de alcance reducido y, en algunos lugares, su uso puede presentar dudas legales.
Protocolos recomendados para empresas y administraciones
Las organizaciones que manejan información crítica o flujos de dinero importantes necesitan ir un paso más allá y establecer procedimientos claros para verificar voces en llamadas sensibles. Un simple guion puede evitar muchos disgustos.
Un primer paso es asegurarse de quién habla. Esto implica empezar siempre por una verificación contextual y humana, idealmente usando una palabra de seguridad acordada con anterioridad. Esa respuesta debería ser revisada por un supervisor o, como mínimo, por un sistema secundario que no dependa solo del audio de la llamada.
Si aun así persisten las dudas, lo prudente es “romper el guion”: interrumpir con naturalidad —por ejemplo, alegando problemas de calidad de la llamada— y devolver la comunicación desde un número oficial que conste en los sistemas internos (CRM, expediente, agenda verificada). Nunca hay que devolver la llamada al número que está entrando en ese momento.
Este tipo de verificación por canal alternativo (out-of-band) es muy efectiva porque obliga al estafador a controlar también el otro canal. Si la persona real atiende al teléfono esperado y el contexto coincide, la probabilidad de que la llamada sea auténtica se dispara.
Cuando ni siquiera así se consigue validar la autenticidad, toca dejar rastro y escalar. Es útil cerrar la conversación con una frase de protocolo, registrar la hora, el origen aparente y las señales raras detectadas (“entonación plana al dar la clave”, “latencia constante antes de contestar”) y pasar el caso al equipo de ciberseguridad o al departamento legal.
Estos protocolos solo funcionan si la plantilla está formada: hay que entrenar a la gente para detectar cambios emocionales extraños, presiones injustificadas y maniobras para evitar el callback, que son tácticas habituales en las estafas con voz real o generada.
Marco legal básico en Europa: qué implica para tu voz
En el ámbito europeo, la voz no es solo un sonido más: el Reglamento General de Protección de Datos (RGPD) considera que la voz es un dato personal. Y si se utiliza para identificar de forma unívoca a una persona, pasa a ser un dato biométrico especialmente protegido.
Eso significa que cualquier sistema que almacene o procese tu voz para identificación necesita una base jurídica sólida (normalmente consentimiento explícito), una finalidad muy clara, recoger solo los datos imprescindibles y definir plazos de conservación y borrado. No vale capturar audios masivamente “por si acaso”.
Además, la nueva Ley de IA de la UE (AI Act) clasifica la identificación biométrica por voz como un ámbito de alto riesgo en muchos casos. Esto obliga a quienes desarrollan y explotan estos sistemas a implantar gestión de riesgos, evaluaciones de impacto en derechos fundamentales y supervisión humana efectiva en las decisiones importantes.
La misma norma prohíbe expresamente usos de la IA que manipulen el comportamiento, exploten vulnerabilidades o simulen emergencias con fines de coacción económica o extracción de datos, incluso si el mensaje no se genera clonando una voz concreta sino con síntesis genérica.
En paralelo, hay investigaciones orientadas a proteger al ciudadano a otro nivel: se está explorando cómo introducir distorsiones imperceptibles para nosotros, pero que confundan a los algoritmos que intentan extraer la huella vocal para entrenar modelos de clonación. La idea es “envenenar” los conjuntos de datos sin estropear la comunicación humana.
En un escenario en el que audio, vídeo y texto pueden ser generados o alterados por IA, aprender a sospechar de las voces demasiado perfectas, verificar siempre que haya dinero o datos de por medio y apoyarse en herramientas de detección como indicios y no como oráculos se ha convertido en una capa más de higiene digital. Combinar oído, contexto, tecnología y protocolos puede marcar la diferencia entre caer en un deepfake de voz bien hecho o detectarlo a tiempo.

Soy un apasionado de la tecnología que ha convertido sus intereses «frikis» en profesión. Llevo más de 10 años de mi vida utilizando tecnología de vanguardia y trasteando todo tipo de programas por pura curiosidad. Ahora me he especializado en tecnología de ordenador y videojuegos. Esto es por que desde hace más de 5 años que trabajo redactando para varias webs en materia de tecnología y videojuegos, creando artículos que buscan darte la información que necesitas con un lenguaje entendible por todos.
Si tienes cualquier pregunta, mis conocimientos van desde todo lo relacionado con el sistema operativo Windows así como Android para móviles. Y es que mi compromiso es contigo, siempre estoy dispuesto a dedicarte unos minutos y ayudarte a resolver cualquier duda que tengas en este mundo de internet.