- Elige escalonadamente: primero ingeniería de prompts, luego prompt tuning y, si hace falta, fine‑tuning.
- RAG potencia las respuestas con recuperación semántica; el prompt correcto evita alucinaciones.
- La calidad de datos y la evaluación continua mandan más que cualquier truco aislado.
La frontera entre lo que consigues con buenos prompts y lo que logras ajustando un modelo (fine tuning) es más fina de lo que parece, pero entenderla marca la diferencia entre respuestas mediocres y sistemas realmente útiles. En esta guía te cuento, con ejemplos y comparativas, cómo elegir y combinar cada técnica para obtener resultados sólidos en proyectos reales.
El objetivo no es quedarnos en la teoría, sino aterrizarlo en el día a día: cuándo te basta con ingeniería de prompts o prompt tuning, cuándo merece la pena invertir en fine tuning, cómo encaja todo esto en flujos RAG y qué buenas prácticas reducen costes, aceleran iteraciones y evitan meterte en callejones sin salida.
Qué son el prompt engineering, el prompt tuning y el fine tuning
Antes de continuar, aclaremos algunos conceptos:
- Prompt engineering (ingeniería de prompts) es el arte de diseñar instrucciones claras, con contexto y expectativas bien definidas para orientar a un modelo ya entrenado. En un chatbot, por ejemplo, define el rol, el tono, el formato de salida y ejemplos para reducir la ambigüedad y mejorar la precisión sin tocar los pesos del modelo.
- Fine‑tuning (ajuste fino) modifica los parámetros internos de un modelo preentrenado con datos adicionales del dominio para afinar su rendimiento en tareas concretas. Es ideal cuando necesitas terminología especializada, decisiones complejas o máxima exactitud en ámbitos sensibles (sanitario, legal, financiero).
- Prompt tuning añade vectores entrenables (soft prompts) que el modelo interpreta junto al texto de entrada. No reentrena todo el modelo: congela sus pesos y optimiza solo esas «pistas» embebidas. Es una vía intermedia eficiente cuando quieres adaptar el comportamiento sin el coste del fine‑tuning completo.
En diseño UX/UI, la ingeniería de prompts mejora la claridad de la interacción humano‑máquina (qué espero y cómo lo pido), mientras que el fine‑tuning eleva la relevancia y consistencia de la salida. Combinados, permiten interfaces más útiles, rápidas y confiables.
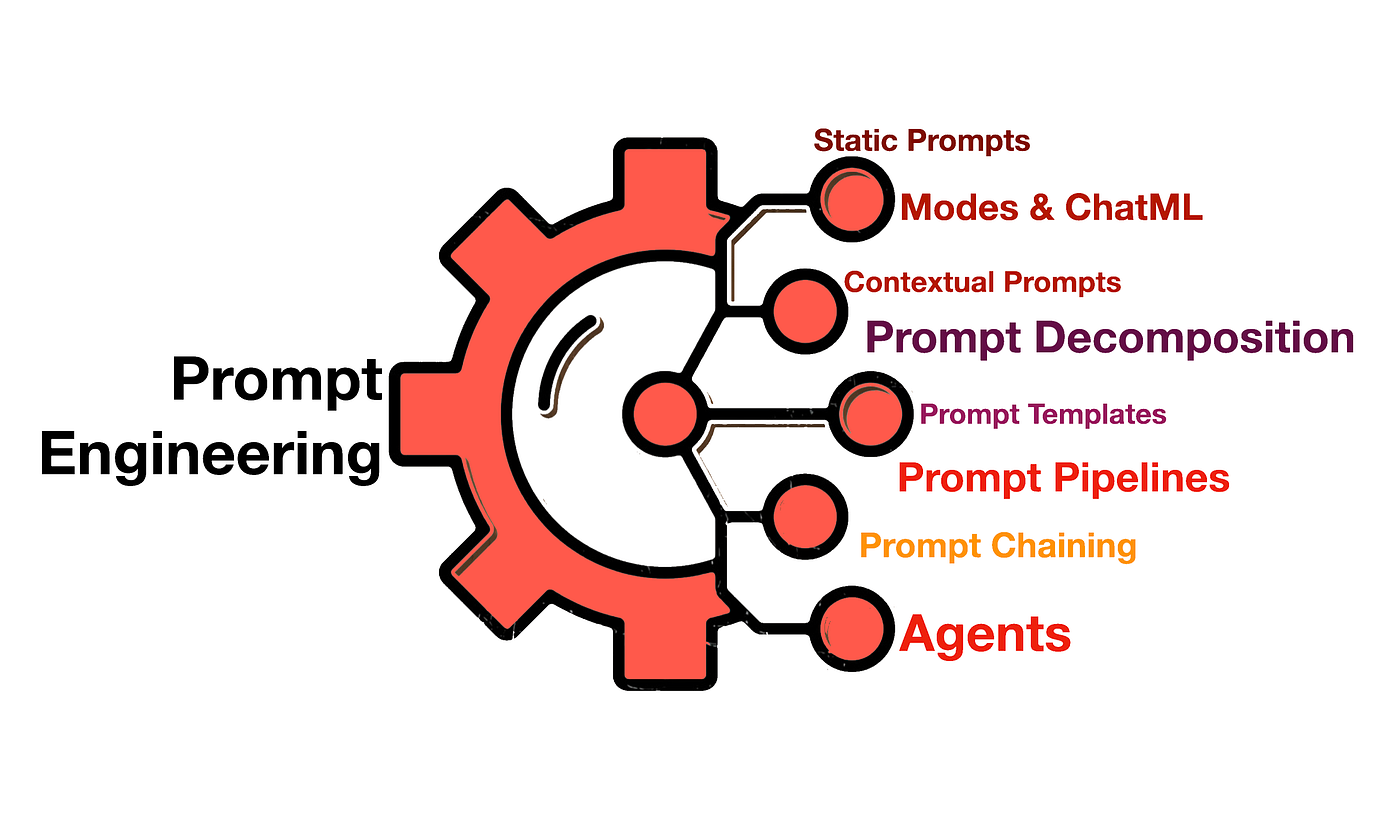
Prompt engineering a fondo: técnicas que sí mueven la aguja
La ingeniería de prompts no consiste en probar a ciegas. Hay métodos sistemáticos que mejoran la calidad sin tocar el modelo ni tus datos base:
- Few‑shot vs zero‑shot. En few‑shot añades pocos ejemplos bien elegidos para que el modelo capte el patrón exacto; en zero‑shot te apoyas en instrucciones y taxonomías claras sin ejemplos.
- Demostraciones en contexto. Enseña el formato esperado (entrada → salida) con mini‑parejas. Esto reduce errores de formato y alinea expectativas, especialmente si exiges campos, etiquetas o estilos concretos en la respuesta.
- Plantillas y variables. Define prompts con espacios reservados (placeholders) para datos cambiantes. El “prompt dinámico” es clave cuando la estructura de entrada varía, por ejemplo, en limpieza de datos de formularios o scraping donde cada registro llega con un formato distinto.
- Verbalizers. Son “traductores” entre el espacio textual del modelo y tus categorías de negocio (p.ej., mapear “contento” → “positivo”). Elegir buenos verbalizers mejora la precisión y la consistencia de etiquetas, especialmente en análisis de sentimiento y clasificación temática.
- Cadenas de prompts (prompt chaining). Divide una tarea compleja en pasos: resumir → extraer métricas → analizar sentimiento. Encadenar etapas hace el sistema más depurable y robusto, y suele elevar la calidad frente a “pedirlo todo de una tacada”.
- Buenas prácticas de formato: marca roles (“Eres un analista…”), define el estilo (“responde en tablas/JSON”), establece criterios de evaluación (“penaliza alucinaciones, cita fuentes cuando existan”) y explicita qué hacer ante incertidumbre (p.ej., “si falta dato, indica ‘desconocido’”).
Componentes del prompt tuning
Además de las instrucciones naturales, el prompt tuning incorpora soft prompts (embeddings entrenables) que se anteponen a la entrada. Durante el entrenamiento, el gradiente ajusta esos vectores para acercar la salida al objetivo sin tocar el resto de pesos del modelo. Es útil cuando quieres portabilidad y costes contenidos.
Cargas el LLM (por ejemplo, un GPT‑2 o similar), preparas tus ejemplos y preprendes los soft prompts a cada entrada. Entrenas solo esos embeddings, de modo que el modelo “ve” un prefacio optimizado que guía su comportamiento en tu tarea.
Aplicación práctica: en un chatbot de atención al cliente, puedes incluir en los soft prompts patrones de preguntas típicas y el tono ideal de respuesta. Esto agiliza la adaptación sin mantener ramas distintas de modelos ni consumir GPU de más.
Fine tuning en profundidad: cuándo, cómo y con qué cautelas
El fine tuning reentrena (parcial o totalmente) los pesos de un LLM con un dataset objetivo para especializarlo. Es la mejor vía cuando la tarea se aleja de lo que el modelo vio en pre-entrenamiento o exige terminología y decisiones finas.
No partes de una pizarra en blanco: modelos chat‑tuned como gpt‑3.5‑turbo ya vienen afinados para seguir instrucciones. Tu fine tuning “repondera” ese comportamiento, lo que puede ser sutil e incierto; por eso conviene experimentar con el diseño de system prompts y entradas.
Algunas plataformas permiten encadenar un fine tune sobre otro ya existente. Esto refuerza señales útiles con menor coste que reentrenar desde cero, y facilita iteraciones guiadas por validación.
Técnicas eficientes como LoRA insertan matrices de bajo rango para adaptar el modelo con pocos parámetros nuevos. Ventaja: menos consumo, despliegues ágiles y reversibilidad (puedes “quitar” la adaptación sin tocar la base).
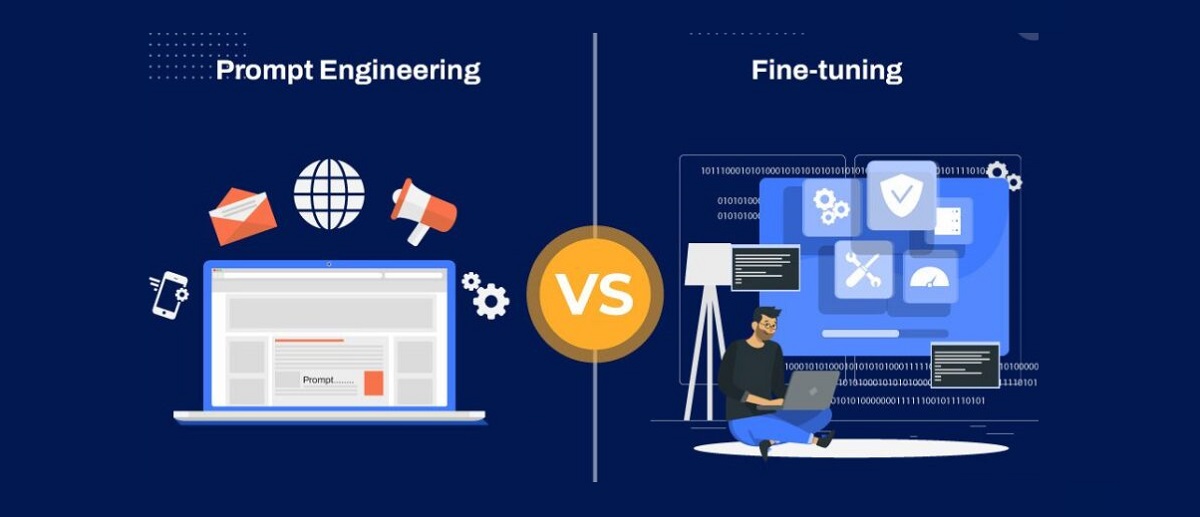
Comparativa: prompt tuning vs fine tuning
- Proceso. Fine tuning actualiza pesos del modelo con un dataset etiquetado de destino; prompt tuning congela el modelo y ajusta solo embeddings entrenables que se concatenan a la entrada; el prompt engineering optimiza el texto de instrucciones y ejemplos sin entrenamiento.
- Ajuste de parámetros. En fine tuning modificas la red; en prompt tuning solo tocas los “soft prompts”; en ingeniería de prompts no hay ajuste paramétrico, solo diseño.
- Formato de entrada. Fine tuning suele respetar el formato original; prompt tuning reformula la entrada con embeddings y plantillas; la ingeniería de prompts aprovecha lenguaje natural estructurado (roles, restricciones, ejemplos).
- Recursos. Fine tuning es más costoso (cómputo, datos y tiempo); prompt tuning es más eficiente; la ingeniería de prompts es la más barata y rápida de iterar si el caso lo permite.
- Objetivo y riesgos. Fine‑tuning optimiza directo a la tarea con riesgo de sobreajuste; prompt tuning alinea con lo ya aprendido por el LLM; la ingeniería de prompts mitiga alucinaciones y errores de formato con buenas prácticas sin tocar el modelo.
Datos y herramientas: la gasolina del rendimiento
- Calidad de datos por delante: curación, deduplicación, balance, cobertura de casos límite y metadatos ricos son el 80% del resultado, tanto si haces fine‑tuning como prompt tuning.
- Automatiza pipelines: plataformas de ingeniería de datos para IA generativa (por ejemplo, soluciones que crean “data products” reutilizables) ayudan a integrar, transformar, entregar y monitorizar datasets para entrenamiento y evaluación. Conceptos como “Nexsets” ilustran cómo empaquetar datos listos para consumo del modelo.
- Bucle de feedback: recoge señales de uso real (éxitos, errores, dudas frecuentes) y retroaliméntalas a tus prompts, soft prompts o datasets. Es la vía más rápida para ganar precisión.
- Reproducibilidad: versiona prompts, soft prompts, datos y pesos adaptados. Sin trazabilidad, es imposible saber qué cambió el rendimiento ni volver a un estado bueno si una iteración sale rana.
- Generalización: al ampliar tareas o idiomas, valida que tus verbalizers, ejemplos y etiquetas no estén sobreadaptados a un dominio. Si cambias de vertical, quizá toque un fine‑tuning ligero o nuevos soft prompts.
- ¿Y si cambio el prompt tras un fine‑tuning? En general, sí: el modelo debería inferir estilos y comportamientos a partir de lo aprendido, no solo repetir tokens. Esa es, precisamente, la gracia de un motor de inferencia.
- Cierra el círculo con métricas: más allá de la exactitud, mide formato correcto, cobertura, citación de fuentes en RAG y satisfacción de usuario. Lo que no se mide no mejora.
Elegir bien entre prompts, prompt tuning y fine‑tuning no va de dogmas sino de contexto: costes, plazos, riesgo de error, disponibilidad de datos y necesidad de especialización. Si clavas esos factores, la tecnología se pone a tu favor y no al revés.
Redactor especializado en temas de tecnología e internet con más de diez años de experiencia en diferentes medios digitales. He trabajado como editor y creador de contenidos para empresas de comercio electrónico, comunicación, marketing online y publicidad. También he escrito en webs de economía, finanzas y otros sectores. Mi trabajo es también mi pasión. Ahora, a través de mis artículos en Tecnobits, intento explorar todas las novedades y nuevas oportunidades que el mundo de la tecnología nos ofrece día a día para mejorar nuestras vidas.