- PerfMon permite medir en tiempo real y registrar a largo plazo con contadores precisos y configurables.
- Los Conjuntos de recopiladores y Logman facilitan capturas repetibles y automatización en servidores.
- Umbrales por memoria, CPU, disco y red ayudan a detectar cuellos de botella y fugas.
- Reliability Monitor complementa el análisis mostrando fallos y problemas de compatibilidad.
PerfMon (Performance Monitor) es la herramienta definitiva para la monitorización en Windows: permite ver en tiempo real, registrar a largo plazo y analizar métricas de rendimiento de CPU, memoria, disco, red y procesos concretos. A diferencia del Administrador de tareas, PerfMon toma muestras a intervalos regulares y registra a disco, lo que resulta ideal para cazar problemas que solo emergen tras horas de ejecución, como crecimientos de memoria o fugas de recursos en servicios y aplicaciones.
En este artículo te mostramos cómo usar PerfMon. Desde elegir y entender los contadores adecuados y ajustar el muestreo y la escala de gráficos, hasta crear Conjuntos de recopiladores de datos para registrar métricas a archivo (BLG/CSV.
Qué es PerfMon y cuándo te conviene usarlo
Performance Monitor (PerfMon) es el visor y registrador nativo de contadores de Windows. Presenta métricas en forma de gráficos y datos crudos obtenidos de contadores del sistema y de aplicaciones (por ejemplo, de .NET CLR o de un proceso específico). Su mayor ventaja frente a utilidades “rápidas” como el Administrador de tareas es que puedes dejarlo funcionando horas o días, con muestras periódicas, para detectar tendencias reales (picos, líneas de base, crecimiento sostenido).
PerfMon es crucial para diagnosticar crecimiento de memoria, pérdidas de manejadores (handles) o hilos, y aislar componentes problemáticos ejecutando pruebas específicas. Por ejemplo, si sospechas de un “memory leak”, activarás contadores como Private Bytes (memoria privada), Handle Count y Thread Count para el proceso afectado, junto con contadores de .NET CLR Memory como # Bytes in all Heaps y Gen 2 heap size cuando la app sea .NET, para ver si el crecimiento ocurre en el GC o fuera de él.
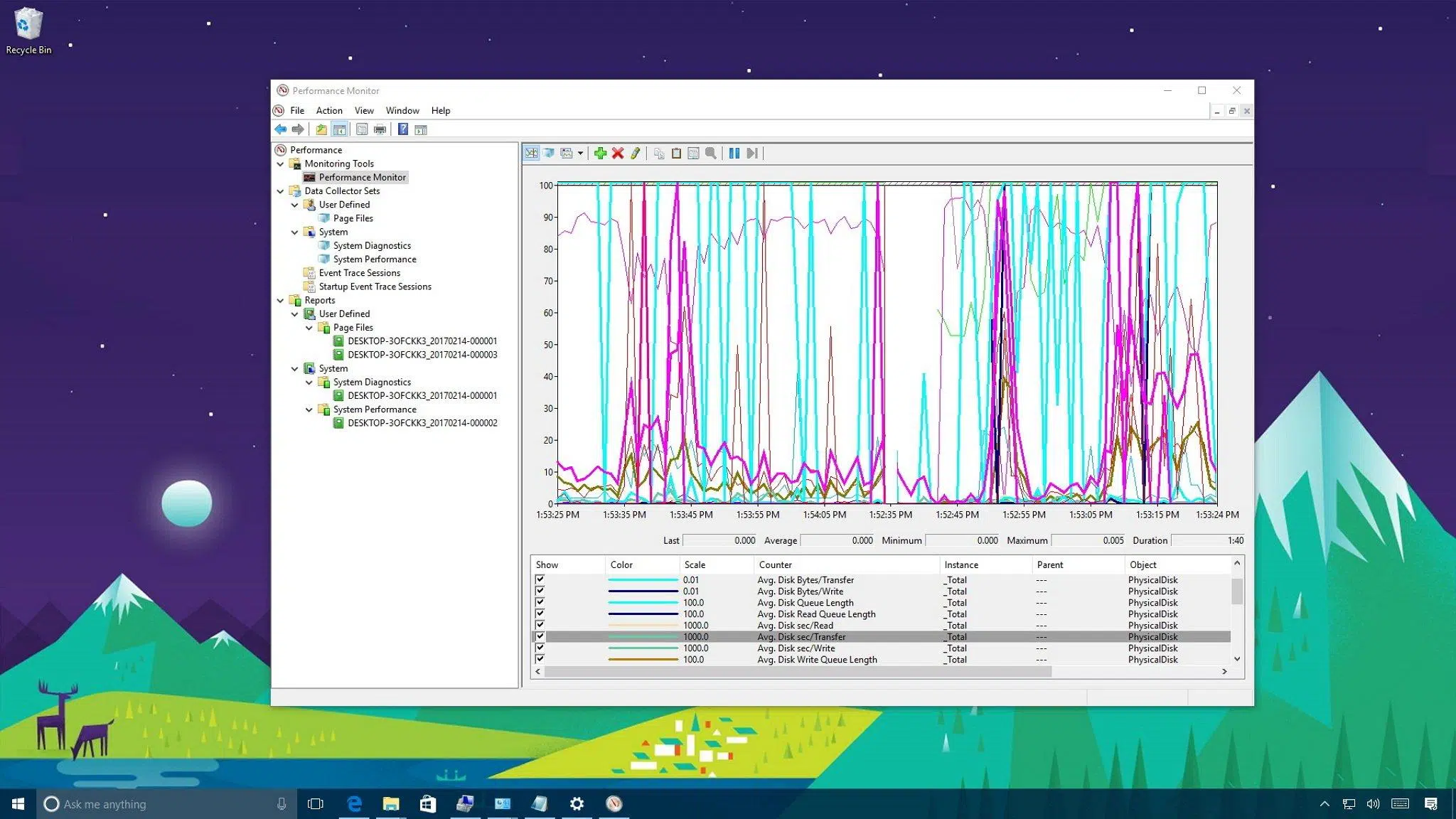
Formas de abrir PerfMon y modos especializados
Puedes abrir PerfMon desde el menú Inicio buscando “performance” o “perfmon”, y ejecutando como administrador cuando vayas a crear registros o consultar equipos remotos.
Si prefieres la línea de comandos (Win+R o CMD), tienes modos directos muy útiles con la siguiente sintaxis:
perfmon </res|report|rel|sys>
¿Qué hace cada opción?
- /res para abrir la vista de recursos
- /report para lanzar el conjunto de recopiladores de diagnóstico del sistema y ver un informe.
- /rel para abrir Reliability Monitor.
- /sys para ir directo al monitor de rendimiento clásico.
Consejo: si quieres revisar la fiabilidad del equipo, perfmon /rel es atajo directo al historial de estabilidad y fallos.
Reliability Monitor también está en Panel de control > Sistema y seguridad > Seguridad y mantenimiento. Otra vía rápida: escribe “reliab” en el buscador del menú Inicio y selecciona “Ver historial de confiabilidad”. Verás eventos críticos, advertencias e información por día o semana, con acceso a detalles técnicos de fallos de aplicaciones y controladores.
Visualización en tiempo real: añadir y comprender contadores
Para ver un gráfico en vivo, abre “Performance Monitor” en el árbol de la izquierda. Si hay contadores precargados y quieres empezar limpio, selecciónalos en la tabla inferior y pulsa Supr. Después, en el área del gráfico, clic derecho > Agregar contadores… para abrir el diálogo con todas las categorías disponibles.
Selecciona la categoría de interés, el contador y la instancia del objeto (por ejemplo, tu proceso). Para diagnosticar memoria y recursos en una app concreta, añade estos contadores clave del grupo Process y .NET CLR Memory cuando corresponda:
- Process \ Private Bytes: memoria privada asignada por el proceso (no compartida con otros). Un crecimiento sostenido indica consumo real de memoria virtual propia.
- Process \ Handle Count: número de manejadores abiertos. Incrementos constantes suelen delatar fugas de recursos (sesiones, objetos del sistema).
- Process \ Thread Count: cantidad de hilos activos en el proceso. Subidas inesperadas pueden apuntar a problemas de concurrencia o a hilos no finalizados.
- .NET CLR Memory \ # Bytes in all Heaps: memoria total para objetos .NET. Si crece sin estabilizarse, revisa la presión de GC y referencias no liberadas.
- .NET CLR Memory \ Gen 2 heap size: tamaño del heap Gen 2 (objetos longevos). Un crecimiento continuo sugiere objetos de larga vida no recolectados.
Interpreta el gráfico con visión crítica. Si observas que Private Bytes sube de forma constante mientras que # Bytes in all Heaps y Gen 2 heap size permanecen estables, el crecimiento no sería del montón .NET sino de memoria nativa/reservas del proceso. Ese patrón suele apuntar a una fuga fuera del GC (por ejemplo, buffers o handles no liberados).
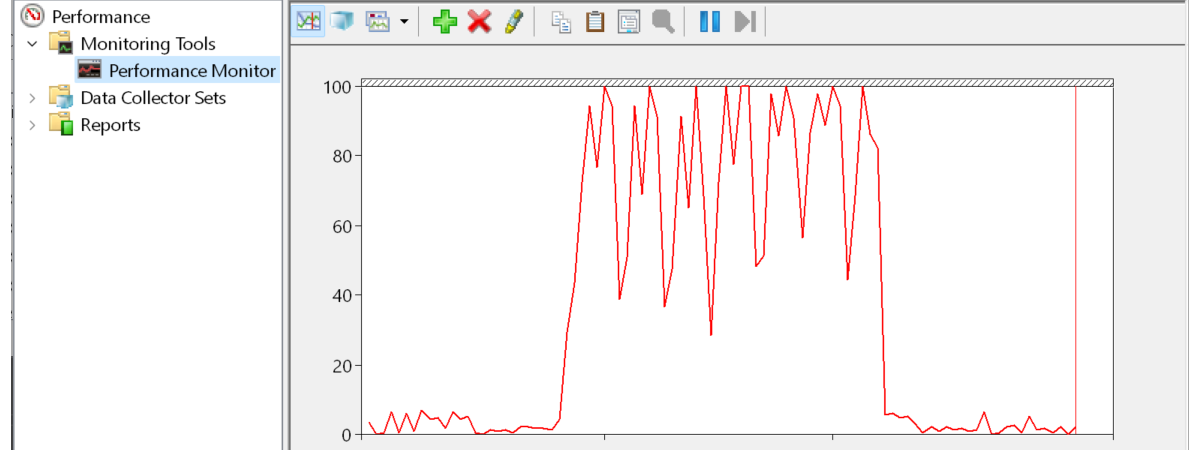
Ajustar la gráfica: escala, intervalo y duración
PerfMon permite ajustar la visibilidad de cada contador y el periodo de historia que ves. Pulsa Ctrl+Mayús+A para seleccionar todos los contadores del listado inferior, clic derecho y elige Escalar contadores seleccionados, así todos serán visibles sin que uno “aplane” al resto.
Abre Propiedades del gráfico con clic derecho > Propiedades… y en la pestaña General fija el muestreo. Por ejemplo, muestra cada 10 s y pon Duración 10000 para cubrir aproximadamente 2,5 horas en la vista. Cuanto más largo el fenómeno, más espaciado debe ser el sampleo para evitar archivos inmensos y sobrecargar el equipo.
Consejo extra: PerfMon expone propiedades y métodos ActiveX, lo que te permite integrarlo o controlarlo desde otras herramientas de desarrollo y hasta incrustarlo como control en una aplicación propia si lo necesitas.
Automatizar con Logman: creación, inicio y parada
Logman.exe es la utilidad de línea de comandos para crear y gestionar conjuntos de contadores. Abre un símbolo del sistema con privilegios de administrador y ejecuta un comando similar al siguiente para crear un conjunto amplio de monitorización continua con archivo circular:
Logman.exe create counter Avamar -o "c:\\perflogs\\Emc-avamar.blg" -f bincirc -v mmddhhmm -max 250 -c "\\LogicalDisk(*)\\*" "\\Memory\\*" "\\Network Interface(*)\\*" "\\Paging File(*)\\*" "\\PhysicalDisk(*)\\*" "\\Processor(*)\\*" "\\Process(*)\\*" "\\Redirector\\*" "\\Server\\*" "\\System\\*" -si 00:00:05
Para arrancar y detener la captura, usa:
Logman.exe start Avamar
Logman.exe stop Avamar
Claves del comando: -f bincirc crea un registro binario circular (-max limita tamaño en MB), -si define el intervalo de muestreo, y -c añade contadores masivamente por objetos y sus instancias. Usa rutas con comillas y escapa las barras invertidas cuando scriptes o exportes la configuración.
¿Cuándo usar Logman? Es ideal para recolectar datos de largo recorrido en servidores, automatizar diagnósticos o estandarizar capturas en múltiples máquinas. Puedes programarlo con el Programador de tareas y rotar archivos sin intervención.
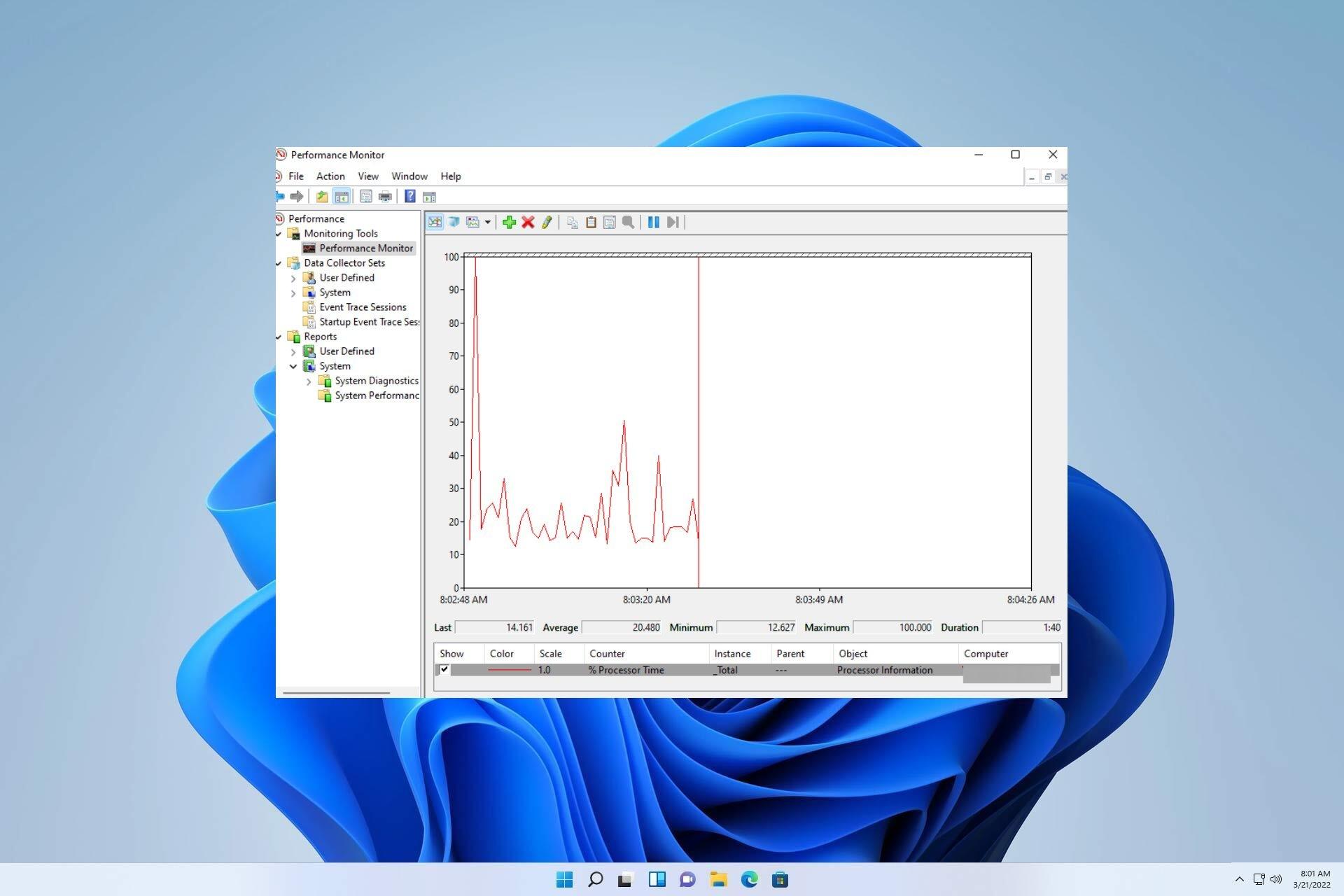
Contadores útiles y umbrales por subsistema
Memoria: vigila capacidad real, presión de paginación y agotamiento de pools del sistema. Estos contadores y orientaciones ayudan a separar síntomas de causas:
- Memory \ % Committed Bytes In Use: porcentaje de memoria comprometida sobre el límite de compromiso. Si supera el 80% de forma sostenida, revisa tamaño del archivo de paginación y consumo real.
- Memory \ Available MBytes: memoria física libre. Investiga si baja < 5% de la RAM repetidamente (y < 1% es crítico).
- Memory \ Committed Bytes: bytes comprometidos totales. No debería variar bruscamente; cambios frecuentes pueden significar expansiones del pagefile.
- Memory \ Pool Nonpaged Bytes: pool no paginado (objetos que no pueden volcar a disco). Saturaciones persistentes (> 80%) se asocian a eventos como 2019 (agotamiento de nonpaged pool).
- Memory \ Pool Paged Bytes: pool paginado. Valores sostenidos > 70% del máximo indican riesgo de evento 2020 (agotamiento de paged pool).
Procesador: busca cargas sostenidas y señales de I/O intensa o drivers ruidosos.
- Processor Information \ % Processor Time (todas las instancias): > 90% sostenido en 1 CPU o > 80% en multiprocesador sugiere CPU saturada.
- Processor \ % Privileged Time: tiempo en modo kernel. Por encima del 30% continuo en servidores de apps/web puede indicar exceso de trabajo en drivers o sistema.
- Processor \ % Interrupt Time y % DPC Time: > 25% apuntan a actividad intensa de dispositivos (NIC, disco, etc.).
- System \ Context Switches/sec y Processor \ Interrupts/sec: útiles para ver presión de cambios de contexto y actividad de interrupciones.
Red: apunta a salud de la NIC y calidad de la comunicación.
- Network Interface \ Packets Received Discarded: debería permanecer cercano a cero; subidas suelen indicar buffers insuficientes/hardware.
- Network Interface \ Packets Received Errors: errores > 2 sostenidos requieren revisión de enlaces/cables/drivers.
Disco: mide saturación, latencia y capacidad.
- PhysicalDisk \ % Idle Time: porcentaje de tiempo inactivo. Bajo de forma sostenida indica disco ocupado; refleja bien la capacidad remanente.
- PhysicalDisk \ Avg. Disk sec/Read y Avg. Disk sec/Write: latencia promedio. Referencias típicas (orientativas): Lecturas excelentes < 8 ms, aceptables < 12 ms, justas < 20 ms, pobres > 20 ms; Escrituras excelentes < 1 ms, buenas < 2 ms, justas < 4 ms, pobres > 4 ms.
- PhysicalDisk \ Avg. Disk Queue Length: colas promedio. Valores inferiores a 2× suelen ser razonables.
- PhysicalDisk \ Split IO/Sec: I/O divididas por fragmentación o tamaños de bloque inadecuados. Cuanto más bajo, mejor.
- LogicalDisk \ % Free Space: deja siempre > 15% libre (recomendable ≥ 25%) en volúmenes lógicos del sistema.
Objetos de disco: físico vs lógico.
- PhysicalDisk agrega el acceso de todas las particiones de un dispositivo físico (identifica el hardware).
- LogicalDisk mide una partición o punto de montaje concreto. Con discos dinámicos, un volumen lógico puede abarcar varios discos físicos y sus contadores reflejarán el conjunto.
Proceso: para correlacionar recursos con comportamiento de una app concreta, vigila Process \ % Processor Time, Private Bytes, Virtual Bytes y Working Set. Handle Count es clave si sospechas fugas de pool; crecimientos de handles a menudo casan con aumentos anómalos de Pool Nonpaged/Paged.
Reliability Monitor: investigar fallos y compatibilidad
El Monitor de confiabilidad de Windows resume estabilidad y eventos por día o semana, clasificando crítico, advertencia e información. Desde cada columna puedes abrir “Ver detalles técnicos” para inspeccionar módulos, códigos y firmas digitales de los binarios implicados.
- Ejemplo práctico: encontrarás entradas como svchost.exe_MapsBroker u otras aplicaciones con bloqueos. A veces el módulo reportado (p. ej., Kernelbase.dll) pertenece al kernel de Windows y está firmado por Microsoft, lo que sugiere que la raíz no es el kernel, sino la aplicación o un complemento que se ejecuta en su espacio de usuario.
- Qué hacer ante una app antigua que falla: ejecuta el solucionador de problemas de compatibilidad y prueba a forzar modo de compatibilidad (por ejemplo, Windows 7) y desactivar el escalado alto de PPP si detectas problemas de interfaz o rendimiento. Este ajuste ha demostrado resolver cierres inesperados en software legacy.
- Vincula hallazgos de estabilidad con PerfMon: combina el historial de fallos con registros de contadores para ver si, antes del crash, subieron Private Bytes, Handle Count o la latencia de disco. Esta correlación te da el hilo del que tirar.
- Cierre práctico: con PerfMon y Reliability Monitor puedes diagnosticar desde los síntomas (crash, lentitud) hacia la causa (fuga de memoria, cuello de disco, CPU al 100%, errores de red), apoyándote en contadores y umbrales que te orientan claramente.
Si necesitas una guía rápida para empezar: abre PerfMon, agrega contadores para el proceso objetivo (Private Bytes, % Processor Time, etc.), ajusta muestreo y duración para cubrir la ventana en la que aparece el problema, registra a archivo con un Conjunto de recopiladores y, si procede, automatiza con Logman en servidores o entornos de pruebas que deban ejecutarse durante horas.
Redactor especializado en temas de tecnología e internet con más de diez años de experiencia en diferentes medios digitales. He trabajado como editor y creador de contenidos para empresas de comercio electrónico, comunicación, marketing online y publicidad. También he escrito en webs de economía, finanzas y otros sectores. Mi trabajo es también mi pasión. Ahora, a través de mis artículos en Tecnobits, intento explorar todas las novedades y nuevas oportunidades que el mundo de la tecnología nos ofrece día a día para mejorar nuestras vidas.